PP-OCR(光学字符识别)
一、简介
PP-OCR 是百度飞桨(PaddlePaddle)开源的一套实用型光学字符识别(OCR)工具库,旨在提供高精度、易用性强、部署灵活的文字识别解决方案,它整合了飞桨在计算机视觉领域的技术积累,支持多语言、多场景的文字检测与识别,广泛应用于文档电子化、车牌识别、工业质检、智能办公等场景,其核心特点包括高精度与实用性的平衡,针对实际业务场景优化,在保证识别精度的同时,通过模型轻量化设计(如移动端模型 PP-OCRv3-mobile)兼顾速度与部署成本,支持中英文、多语言(日语、韩语、法语等)及特殊场景(如弯曲文本、模糊文本)的识别。
工程目录
PP-OCR
├─cpp
│ ├─dependencies ##C++例程依赖
│ │
│ └─ppocr_bmcv
│ │ CMakeLists.txt ##交叉编译所需文件
│ │ ppocr_bmcv.soc ##提供的交叉编译好的可执行文件
│ │
│ ├─include ##交叉编译的依赖项
│ │ clipper.h
│ │ postprocess.hpp
│ │ ppocr_cls.hpp
│ │ ppocr_det.hpp
│ │ ppocr_rec.hpp
│ │
│ ├─src ##交叉编译源码
│ │ clipper.cpp
│ │ main.cpp
│ │ postprocess.cpp
│ │ ppocr_cls.cpp
│ │ ppocr_det.cpp
│ │ ppocr_rec.cpp
│ │
│ └─thirdparty ##交叉编译第三方库
│ cnpy.cpp
│ cnpy.h
│
├─docs ##帮助文档
│ │ PP-OCR.md
│ │
│ └─images
├─python ##python例程所需文件
│ ppocr_cls_opencv.py
│ ppocr_det_opencv.py
│ ppocr_rec_opencv.py
│ ppocr_system_opencv.py
│ requirements.txt
│
├─scripts
│ download.sh ##下载数据集和模型所需的脚本文件
│
└─tools ##比较和评估的文件
compare_statis.py
eval_icdar.py二、运行步骤
在运行测试例程之前需要下载所需的数据集和模型。
#安装下载工具
pip3 install dfss --upgrade
#执行下载脚本
bash scripts/download.sh1.python例程
1.1文本检测推理测试
ppocr_det_opencv.py参数说明如下:
usage: ppocr_det_opencv.py [-h] [--dev_id DEV_ID] [--input INPUT] [--bmodel_det BMODEL_DET]
optional arguments:
-h, --help show this help message and exit
--dev_id DEV_ID tpu card id
--input INPUT input image directory path
--bmodel_det BMODEL_DET
bmodel path文本检测测试实例如下:
# 程序会自动根据文件夹中的图片数量来选择1batch或者4batch,优先选择4batch推理。
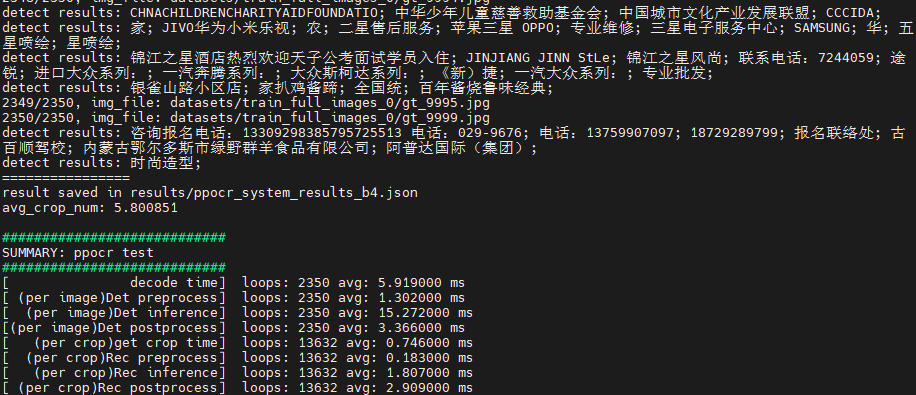
python3 python/ppocr_det_opencv.py --input datasets/cali_set_det --bmodel_det models/BM1684X/ch_PP-OCRv4_det_fp32.bmodel --dev_id 0执行完成后,会将预测图片保存在results/det_results文件夹下。

1.2文本识别推理测试
ppocr_rec_opencv.py参数说明如下:
usage: ppocr_rec_opencv.py [-h] [--dev_id DEV_ID] [--input INPUT] [--bmodel_rec BMODEL_REC] [--img_size IMG_SIZE] [--char_dict_path CHAR_DICT_PATH] [--use_space_char USE_SPACE_CHAR] [--use_beam_search]
[--beam_size {1~40}]
optional arguments:
-h, --help show this help message and exit
--dev_id DEV_ID tpu card id
--input INPUT input image directory path
--bmodel_rec BMODEL_REC
recognizer bmodel path
--img_size IMG_SIZE You should set inference size [width,height] manually if using multi-stage bmodel.
--char_dict_path CHAR_DICT_PATH
--use_space_char USE_SPACE_CHAR
--use_beam_search Enable beam search
--beam_size {1~40} Only valid when using beam search, valid range 1~40文本识别测试实例如下:
# 程序会自动根据文件夹中的图片数量来选择1batch或者4batch,优先选择4batch推理。
python3 python/ppocr_rec_opencv.py --input datasets/cali_set_rec --bmodel_rec models/BM1684X/ch_PP-OCRv4_rec_fp32.bmodel --dev_id 0 --img_size [[640,48],[320,48]] --char_dict_path datasets/ppocr_keys_v1.txt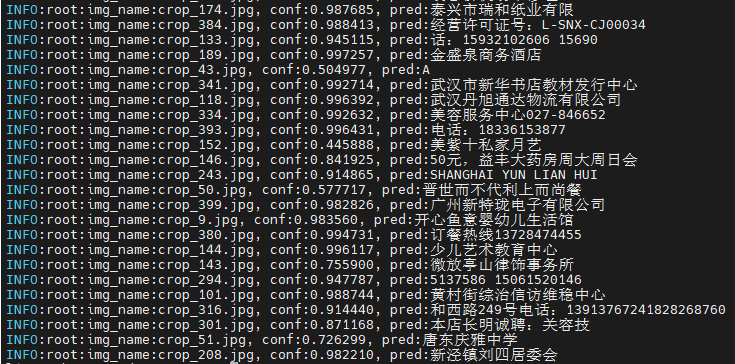
1.3全流程推理测试
ppocr_system_opencv.py参数说明如下:
usage: ppocr_system_opencv.py [-h] [--input INPUT] [--dev_id DEV_ID] [--batch_size BATCH_SIZE] [--bmodel_det BMODEL_DET] [--det_limit_side_len DET_LIMIT_SIDE_LEN] [--bmodel_rec BMODEL_REC] [--img_size IMG_SIZE]
[--char_dict_path CHAR_DICT_PATH] [--use_space_char USE_SPACE_CHAR] [--use_beam_search]
[--beam_size {1~40}] [--rec_thresh REC_THRESH] [--use_angle_cls]
[--bmodel_cls BMODEL_CLS] [--label_list LABEL_LIST] [--cls_thresh CLS_THRESH]
optional arguments:
-h, --help show this help message and exit
--input INPUT input image directory path
--dev_id DEV_ID tpu card id
--batch_size BATCH_SIZE
img num for a ppocr system process launch.
--bmodel_det BMODEL_DET
detector bmodel path
--det_limit_side_len DET_LIMIT_SIDE_LEN
--bmodel_rec BMODEL_REC
recognizer bmodel path
--img_size IMG_SIZE You should set inference size [width,height] manually if using multi-stage bmodel.
--char_dict_path CHAR_DICT_PATH
--use_space_char USE_SPACE_CHAR
--use_beam_search Enable beam search
--beam_size {1~40} Only valid when using beam search, valid range 1~40
--rec_thresh REC_THRESH
--use_angle_cls
--bmodel_cls BMODEL_CLS
classifier bmodel path
--label_list LABEL_LIST
--cls_thresh CLS_THRESH测试实例如下:
python3 python/ppocr_system_opencv.py --input datasets/train_full_images_0 \
--batch_size 4 \
--bmodel_det models/BM1684X/ch_PP-OCRv4_det_fp32.bmodel \
--bmodel_rec models/BM1684X/ch_PP-OCRv4_rec_fp32.bmodel \
--dev_id 0 \
--img_size [[640,48],[320,48]] \
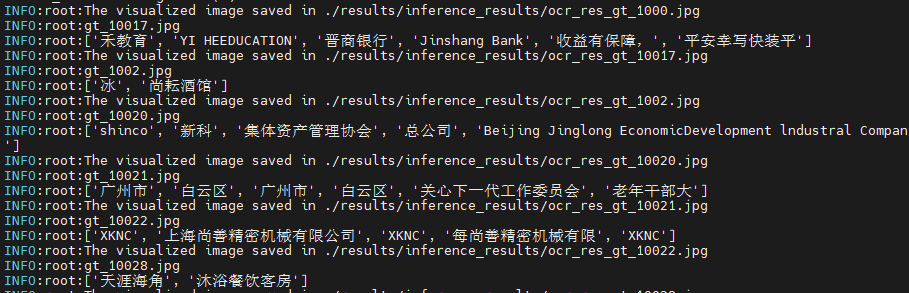
--char_dict_path datasets/ppocr_keys_v1.txt执行完成后,会打印预测的字段,同时会将预测的可视化结果保存在results/inference_results文件夹下,推理结果会保存在results/ppocr_system_results_b4.json下。

2.C++例程
1.交叉编译环境搭建
1.1编译环境
C++程序要在板端运行,是需要对依赖文件进行编译的。这里我们为了节省边缘设备的压力,选择使用一个X86的linux环境进行交叉编译。
搭建交叉编译环境,这里提供两种方式:
(1)通过apt安装交叉编译工具链:
如果您的系统和目标SoC平台的libc版本相同(可通过ldd --version命令进行查询),那么您可以使用如下命令安装:
sudo apt-get install gcc-aarch64-linux-gnu g++-aarch64-linux-gnu卸载方法:
sudo apt remove cpp-*-aarch64-linux-gnu如果您的环境不满足上述要求,建议使用第(2)种方法。
(2)通过docker搭建交叉编译环境:
可以使用我们提供的docker镜像--stream_dev.tar作为交叉编译环境。
如果是首次使用Docker, 可执行下述命令进行安装和配置(仅首次执行):
sudo apt install docker.io
sudo systemctl start docker
sudo systemctl enable docker
sudo groupadd docker
sudo usermod -aG docker $USER
newgrp docker在下载好的镜像目录中加载镜像
docker load -i stream_dev.tar可以通过docker images查看加载好的镜像,默认为stream_dev:latest
创建容器
docker run --privileged --name stream_dev -v $PWD:/workspace -it stream_dev:latest
# stream_dev只是举个名字的例子, 请指定成自己想要的容器的名字容器中的workspace目录会挂载到您运行docker run时所在的宿主机目录,您可以在此容器中编译项目。workspace目录在根目录下,该目录下的改动会映射到本地目录中对应文件的改动。
注意:创建容器时需要到soc-sdk(依赖编译环境)的父目录以及以上目录
1.2打包依赖文件
打包libsophon
对libsophon_soc_x.y.z_aarch64.tar.gz,x.y.z表示版本号,并进行解压。
# 创建依赖文件的根目录 mkdir -p soc-sdk # 解压libsophon_soc_x.y.z_aarch64.tar.gz tar -zxf libsophon_soc_${x.y.z}_aarch64.tar.gz # 将相关的库目录和头文件目录拷贝到依赖文件根目录下 cp -rf libsophon_soc_${x.y.z}_aarch64/opt/sophon/libsophon-${x.y.z}/lib soc-sdk cp -rf libsophon_soc_${x.y.z}_aarch64/opt/sophon/libsophon-${x.y.z}/include soc-sdk打包sophon-ffmpeg和sophon-opencv
对sophon-mw-soc_x.y.z_aarch64.tar.gz,x.y.z表示版本号,并进行解压。
# 解压sophon-mw-soc_x.y.z_aarch64.tar.gz tar -zxf sophon-mw-soc_${x.y.z}_aarch64.tar.gz # 将ffmpeg和opencv的库目录和头文件目录拷贝到soc-sdk目录下 cp -rf sophon-mw-soc_${x.y.z}_aarch64/opt/sophon/sophon-ffmpeg_${x.y.z}/lib soc-sdk cp -rf sophon-mw-soc_${x.y.z}_aarch64/opt/sophon/sophon-ffmpeg_${x.y.z}/include soc-sdk cp -rf sophon-mw-soc_${x.y.z}_aarch64/opt/sophon/sophon-opencv_${x.y.z}/lib soc-sdk cp -rf sophon-mw-soc_${x.y.z}_aarch64/opt/sophon/sophon-opencv_${x.y.z}/include soc-sdk
1.3进行交叉编译
交叉编译环境搭建好后,使用交叉编译工具链编译生成可执行文件:
cd cpp/ppocr_bmcv
mkdir build && cd build
#请根据实际情况修改-DSDK的路径,需使用绝对路径。
cmake -DTARGET_ARCH=soc -DSDK=/workspace/soc-sdk/ ..
make编译完成后在对应的目录会生成.soc文件,如:cpp/ppocr_bmcv/ppocr_bmcv.soc,也提供了该文件,可直接使用。
2.推理测试
需将交叉编译生成的可执行文件及所需的模型、测试数据拷贝到SoC平台(即BM1684X开发板)中测试。
参数说明
可执行程序默认有一套参数,请注意根据实际情况进行传参,ppocr_bmcv.soc具体参数说明如下:
Usage: ppocr_bmcv.soc [params]
--batch_size (value:4)
ppocr system batchsize
--beam_size (value:3)
beam size, default 3, available 1-40, only valid when using beam search
--bmodel_cls (value:../../models/BM1684X/ch_PP-OCRv3_cls_fp32.bmodel)
cls bmodel file path, unsupport now.
--bmodel_det (value:../../models/BM1684X/ch_PP-OCRv4_det_fp32.bmodel)
det bmodel file path
--bmodel_rec (value:../../models/BM1684X/ch_PP-OCRv4_rec_fp32.bmodel)
rec bmodel file path
--dev_id (value:0)
TPU device id
--help (value:true)
print help information.
--input (value:../../datasets/cali_set_det)
input path, images directory
--labelnames (value:../../datasets/ppocr_keys_v1.txt)
class names file path
--rec_thresh (value:0.5)
recognize threshold
--use_beam_search (value:false)
beam search trigger图片测试
图片测试实例如下,支持对整个图片文件夹进行测试。
#文件加上可执行权限
chmod 755 cpp/ppocr_bmcv/ppocr_bmcv.soc
#执行文件
./cpp/ppocr_bmcv/ppocr_bmcv.soc --input=datasets/train_full_images_0 \
--batch_size=4 \
--bmodel_det=models/BM1684X/ch_PP-OCRv4_det_fp32.bmodel \
--bmodel_rec=models/BM1684X/ch_PP-OCRv4_rec_fp32.bmodel \
--labelnames=datasets/ppocr_keys_v1.txt测试结束后,会将预测的图片保存在results/images下,预测的结果保存在results/ 下,同时会打印预测结果、推理时间等信息。