模型量化
简介
TPU-MLIR是算能深度学习处理器的编译器工程。该工程提供了一套完整的工具链, 其可以将 不同框架下预训练的神经网络, 转化为可以在算能智能视觉深度学习处理器上高效运算的文件 bmodel。 代码已经开源到github: https://github.com/sophgo/tpu-mlir 。
论文https://arxiv.org/abs/2210.15016 描述了TPU-MLIR的整体设计思路。
TPU-MLIR的整体架构如下:
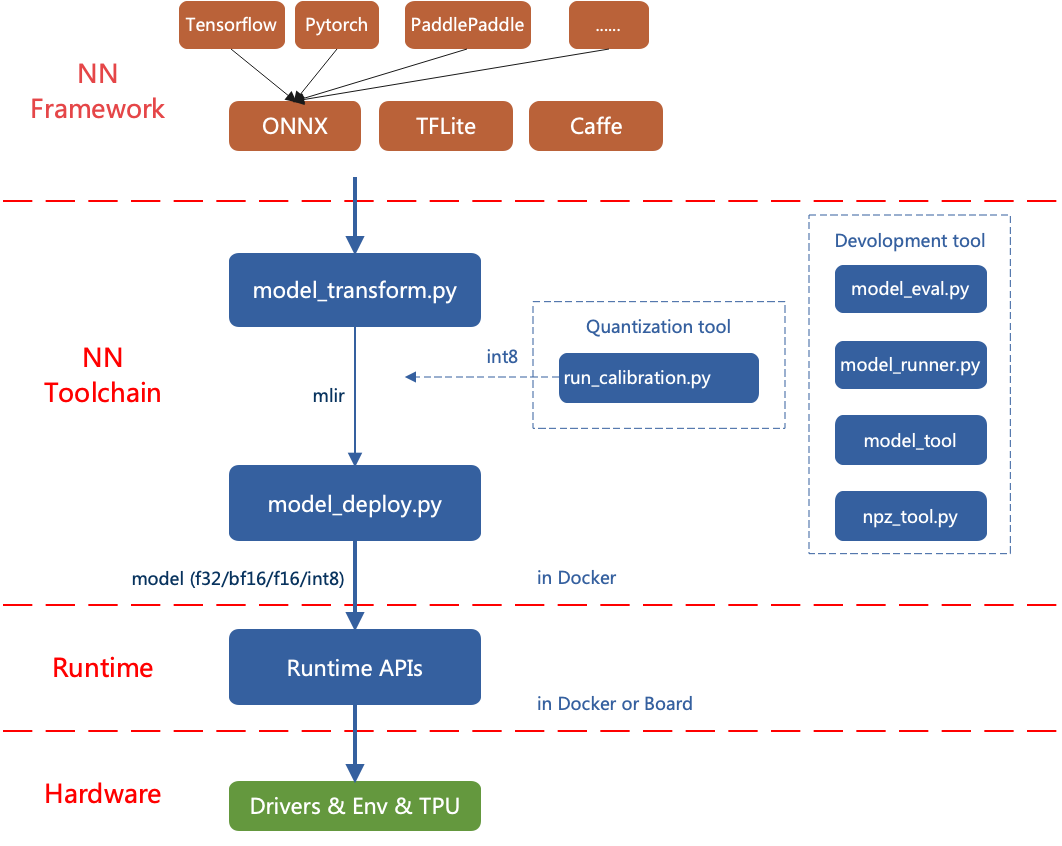
目前直接支持的框架有ONNX、Pytorch、Caffe和TFLite。其他框架的模型需要转换成onnx模型。如何将其他深 度学习架构的网络模型转换成onnx, 可以参考onnx官网:https://github.com/onnx/tutorials。
转模型需要在指定的docker执行, 主要分两步, 一是通过 model_transform.py 将原始模型 转换成mlir文件, 二是通过 model_deploy.py 将mlir文件转换成bmodel。
如果要转INT8模型, 则需要调用 run_calibration.py 生成校准表, 然后传给 model_deploy.py。
如果INT8模型不满足精度需要, 可以调用 run_qtable.py 生成量化表, 用来决定哪些层采用浮点计算, 然后传给 model_deploy.py 生成混精度模型。
1.搭建TPU-MLIR环境
1.1基础环境
为了缓解板端存储压力,使用非BM1684X的linux系统(这里以WSL为例)进行模型量化和转换;如果你的环境满足python >= 3.10 以及 ubuntu:22.04,则可以跳过docker环境配置(本小节)的过程。
因为在模型转换和量化的过程中会受到libc版本的影响,所以这里使用官方的镜像进行环境搭建;TPU-MLIR在Docker环境开发, 配置好Docker就可以编译和运行了。
如果是首次使用Docker, 可执行下述命令进行安装和配置(仅首次执行需要该操作):
sudo apt install docker.io
sudo systemctl start docker
sudo systemctl enable docker
sudo groupadd docker
sudo usermod -aG docker $USER
newgrp docker从dockerhub拉取需要的镜像
docker pull sophgo/tpuc_dev:latest如果拉取失败可以通过wget直接下载镜像到本地
#使用wget下载所需的镜像
wget https://sophon-assets.sophon.cn/sophon-prod-s3/drive/25/04/15/16/tpuc_dev_v3.4.tar.gz
#加载镜像
docker load -i tpuc_dev_v3.4.tar.gz启动镜像环境
#首次创建tpumlir环境使用下面命令,--name tpumlir这里名字可自定义设置
docker run --privileged --name tpumlir -v $PWD:/workspace -it sophgo/tpuc_dev:latest
#非首次创建直接使用下面命令
docker run -v $PWD:/workspace -it sophgo/tpuc_dev:latest1.2安装TPU-MLIR
TPU-MLIR的安装方式提供了以下三种
(1)直接从pypi下载并安装(推荐):
pip install tpu_mlir -i https://pypi.tuna.tsinghua.edu.cn/simple(2)从TPU-MLIR Github下载最新tpu_mlir-*-py3-none-any.whl,然后使用pip安装:
pip install tpu_mlir-*-py3-none-any.whl提示
TPU-MLIR在对不同框架模型处理时所需的依赖不同,对于onnx或torch生成的模型文件, 使用下面命令安装额外的依赖环境:
pip install tpu_mlir[onnx] -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install tpu_mlir[torch] -i https://pypi.tuna.tsinghua.edu.cn/simple目前支持五种配置: onnx, torch, tensorflow, caffe, paddle。可使用一条命令安装多个配置,也可直接安装全部依赖环境:
pip install tpu_mlir[onnx,torch,caffe] -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install tpu_mlir[all] -i https://pypi.tuna.tsinghua.edu.cn/simple(3)如果您获取了类似tpu-mlir_${version}-${hash}-${date}.tar.gz这种形式的发布包,该发布包可以从下载sophon-SDK并查看子目录获得(一般在SDK-23.09-LTS-SP4\tpu-mlir_20231116_054500目录下),可以通过这种方式配置:
#可通过下面命令选择下载SDK
wget https://sophon-assets.sophon.cn/sophon-prod-s3/drive/24/12/31/10/SDK-23.09-LTS-SP4.zip
# 如果此前有通过pip安装过mlir,需要卸载掉
pip uninstall tpu_mlir
#解压安装发布包
tar xvf tpu-mlir_${version}-${hash}-${date}.tar.gz
cd tpu-mlir_${version}-${hash}-${date}
source envsetup.sh #配置环境变量建议TPU-MLIR的镜像仅用于编译和量化模型,程序编译和运行请在开发和运行环境中进行。更多TPU-MLIR的教程可参考相关网页。
2.编译模型
本节以 yolov5s.onnx 为例, 介绍如何编译迁移一个onnx模型至BM1684X 平台运行。其他模型可以参考相关示例。
2.1配置工程目录
请从Github的 Assets 处下载 tpu-mlir-resource.tar 并解压,解压后将文件夹重命名为 tpu_mlir_resource :
#可手动下载,也可通过下面命令使用wget下载,推荐手动
wget https://github.com/sophgo/tpu-mlir/releases/download/v1.20/tpu-mlir-resource.tar
#解压工程目录
tar -xvf tpu-mlir-resource.tar
#修改文件名称
mv regression/ tpu-mlir-resource/提示
tpu-mlir-resource.tar是示例资源文件,您如果想要转化自己的模型,该文件不是必须的,相关配置可以查询开发手册。
建立 model_yolov5s_onnx 目录, 并把模型文件和图片文件都放入 model_yolov5s_onnx 目录中。
操作如下:
mkdir model_yolov5s_onnx && cd model_yolov5s_onnx
wget https://github.com/ultralytics/yolov5/releases/download/v6.0/yolov5s.onnx
cp -rf tpu_mlir_resource/dataset/COCO2017 .
cp -rf tpu_mlir_resource/image .
mkdir workspace && cd workspace2.2ONNX转MLIR
如果模型是图片输入, 在转模型之前我们需要了解模型的预处理。如果模型用预处理后的npz文件做输入, 则不需要考虑预处理。
预处理过程用公式表达如下( x代表输入): $$ y=(x-mean)*scale $$ 官网yolov5的图片是rgb格式, 每个值会乘以 1/255 , 转换成mean和scale对应为 0.0,0.0,0.0 和 0.0039216,0.0039216,0.0039216 。
模型转换命令如下:
$ model_transform \
--model_name yolov5s \
--model_def ../yolov5s.onnx \
--input_shapes [[1,3,640,640]] \
--mean 0.0,0.0,0.0 \
--scale 0.0039216,0.0039216,0.0039216 \
--keep_aspect_ratio \
--pixel_format rgb \
--output_names 350,498,646 \
--test_input ../image/dog.jpg \
--test_result yolov5s_top_outputs.npz \
--mlir yolov5s.mlirmodel_transform 主要参数说明如下(完整介绍请参见TPU-MLIR开发参考手册用户界面章节):
| 参数名 | 必选? | 说明 |
|---|---|---|
| model_name | 是 | 指定模型名称 |
| model_def | 是 | 指定模型定义文件, 比如 .onnx 或 .tflite 或 .prototxt 文件 |
| input_shapes | 否 | 指定输入的shape, 例如 [[1,3,640,640]] ; 二维数组, 可以支持多输入情况 |
| input_types | 否 | 指定输入的类型, 例如int32; 多输入用,隔开; 不指定情况下默认处理为float32 |
| resize_dims | 否 | 原始图片需要resize之后的尺寸; 如果不指定, 则resize成模型的输入尺寸 |
| keep_aspect_ratio | 否 | 在Resize时是否保持长宽比, 默认为false; 设置时会对不足部分补0 |
| mean | 否 | 图像每个通道的均值, 默认为0.0,0.0,0.0 |
| scale | 否 | 图片每个通道的比值, 默认为1.0,1.0,1.0 |
| pixel_format | 否 | 图片类型, 可以是rgb、bgr、gray、rgbd四种格式, 默认为bgr |
| channel_format | 否 | 通道类型, 对于图片输入可以是nhwc或nchw, 非图片输入则为none, 默认为nchw |
| output_names | 否 | 指定输出的名称, 如果不指定, 则用模型的输出; 指定后用该指定名称做输出 |
| test_input | 否 | 指定输入文件用于验证, 可以是图片或npy或npz; 可以不指定, 则不会进行正确性验证 |
| test_result | 否 | 指定验证后的输出文件 |
| excepts | 否 | 指定需要排除验证的网络层的名称, 多个用 , 隔开 |
| mlir | 是 | 指定输出的mlir文件名称和路径 |
转成mlir文件后, 会生成一个 ${model_name}_in_f32.npz 文件, 该文件是模型的输入文件。
2.3MLIR转F16模型
将mlir文件转换成f16的bmodel, 操作方法如下:
model_deploy \
--mlir yolov5s.mlir \
--quantize F16 \
--processor bm1684x \
--test_input yolov5s_in_f32.npz \
--test_reference yolov5s_top_outputs.npz \
--model yolov5s_1684x_f16.bmodel编译完成后, 会生成名为 yolov5s_1684x_f16.bmodel 的文件。
model_deploy 的主要参数说明如下(完整介绍请参见TPU-MLIR开发参考手册用户界面章节):
| 参数名 | 必选? | 说明 |
|---|---|---|
| mlir | 是 | 指定mlir文件 |
| quantize | 是 | 指定默认量化类型, 支持F32/F16/BF16/INT8 |
| processor | 是 | 指定模型将要用到的平台, 支持bm1690, bm1688, bm1684x, bm1684, cv186x, cv183x, cv182x, cv181x, cv180x |
| calibration_table | 否 | 指定校准表路径, 当存在INT8量化的时候需要校准表 |
| tolerance | 否 | 表示 MLIR 量化后的结果与 MLIR fp32推理结果相似度的误差容忍度 |
| test_input | 否 | 指定输入文件用于验证, 可以是图片或npy或npz; 可以不指定, 则不会进行正确性验证 |
| test_reference | 否 | 用于验证模型正确性的参考数据(使用npz格式)。其为各算子的计算结果 |
| compare_all | 否 | 验证正确性时是否比较所有中间结果, 默认不比较中间结果 |
| excepts | 否 | 指定需要排除验证的网络层的名称, 多个用,隔开 |
| op_divide | 否 | cv183x/cv182x/cv181x/cv180x only, 尝试将较大的op拆分为多个小op以达到节省ion内存的目的, 适用少数特定模型 |
| model | 是 | 指定输出的model文件名称和路径 |
| num_core | 否 | 当target选择为bm1688时,用于选择并行计算的tpu核心数量,默认设置为1个tpu核心 |
| skip_validation | 否 | 跳过验证bmodel正确性环节,用于提升模型部署的效率,默认执行bmodel验证 |
2.5 MLIR转INT8模型
2.5.1 生成校准表
转INT8模型前需要跑calibration, 得到校准表; 输入数据的数量根据情况准备100~1000张左右。
然后用校准表, 生成对称或非对称bmodel。如果对称符合需求, 一般不建议用非对称, 因为 非对称的性能会略差于对称模型。
这里用现有的100张来自COCO2017的图片举例, 执行calibration:
run_calibration yolov5s.mlir \
--dataset ../COCO2017 \
--input_num 100 \
-o yolov5s_cali_table运行完成后会生成名为 yolov5s_cali_table 的文件, 该文件用于后续编译INT8模型的输入文件。
2.5.2. 编译为INT8对称量化模型
转成INT8对称量化模型, 执行如下命令:
model_deploy \
--mlir yolov5s.mlir \
--quantize INT8 \
--calibration_table yolov5s_cali_table \
--processor bm1684x \
--test_input yolov5s_in_f32.npz \
--test_reference yolov5s_top_outputs.npz \
--tolerance 0.85,0.45 \
--model yolov5s_1684x_int8_sym.bmodel编译完成后, 会生成名为 yolov5s_1684x_int8_sym.bmodel 的文件。
2.6 效果对比
在本发布包中有用python写好的yolov5用例, 使用 detect_yolov5 命令, 用于对图片进行目标检测。
该命令对应源码路径 {package/path/to/tpu_mlir}/python/samples/detect_yolov5.py 。
阅读该代码可以了解模型是如何使用的: 先预处理得到模型的输入, 然后推理得到输出, 最后做后处理。
用以下代码分别来验证onnx/f16/int8的执行结果。
onnx模型的执行方式如下, 得到 dog_onnx.jpg :
detect_yolov5 \
--input ../image/dog.jpg \
--model ../yolov5s.onnx \
--output dog_onnx.jpg
f16 bmodel的执行方式如下, 得到 dog_f16.jpg :
detect_yolov5 \
--input ../image/dog.jpg \
--model yolov5s_1684x_f16.bmodel \
--output dog_f16.jpg
int8对称bmodel的执行方式如下, 得到 dog_int8_sym.jpg :
detect_yolov5 \
--input ../image/dog.jpg \
--model yolov5s_1684x_int8_sym.bmodel \
--output dog_int8_sym.jpg