Qwen3-chat-DEMO
1. Introduction
Qwen3 (Tongyi Qianwen 3) is a new generation of large language model (LLM) series launched by Alibaba, and is the latest iteration of the Tongyi Qianwen (Qwen) family. It has been significantly upgraded in terms of performance, multimodal capabilities, and long text processing, and is suitable for tasks such as natural language understanding, code generation, mathematical reasoning, and multi-round dialogue.
1. Features
- 1. Stronger performance
Parameter scale: covers multiple scales such as 1.8B, 7B, 14B, 72B, etc. to meet the needs of different scenarios.
Benchmark performance: Leading similar models in Chinese and English evaluations such as MMLU, C-Eval, GSM8K, and HumanEval.
Long text support: The context window is expanded to 128K tokens, which is suitable for tasks such as long document analysis and code understanding. - 2. Open source and ecology
Open source agreement: Some models adopt Apache 2.0 license, which allows commercial use and research.
Tool chain support: Provide quantization, fine-tuning, API and other supporting tools, and adapt to GPU/TPU hardware (such as BM1684X). - 3. Reasoning optimization
Low resource adaptation: Supports 4-bit/8-bit quantization and can be deployed on consumer-grade GPUs (such as RTX 4090) or edge devices (such as BM1684X TPU).
Dynamic computing: Adaptively adjust computing resources to balance speed and accuracy.
2. Project Directory
Personal demonstration project directory
Qwen3
├── cpp_demo
├── Models
│ └── BM1684X
│ └── qwen3-4b_w4bf16_seq512_bm1684x_1dev_20250429_120231.bmodel # BM1684X qwen3-4b model
├── python_demo
│ ├── config # Configuration files
│ ├── chat.cpp # Startup program
│ ├── CMakeLists.txt # Create a Python chat module
│ ├── pipeline.py # Execution file
│ └── README.md # Instruction document
└── README.md # Instruction document2. Operation steps
1. Prepare Python environment, data and model
1.1 First upgrade the python version to 3.10
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt update
sudo apt install python3.10 python3.10-dev
# Create a virtual environment (without pip packages)
# !!!Switch to the virtual environment according to the steps every time you run it!!!
cd /data
# Create a virtual environment (without pip)
python3.10 -m venv --without-pip myenv
# Enter the virtual environment
source myenv/bin/activate
# Manually install pip
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
python get-pip.py
rm get-pip.py
# Install dependent libraries
pip3 install torchvision pillow qwen_vl_utils transformers --upgrade1.2 Copy the official Qwen3 project directory of Suanneng (or copy and upload Qwen3 to /data in the box)
git clone https://github.com/sophgo/LLM-TPU.git
cd sophgo/LLM-TPU/models/Qwen3
cd /data/Qwen3 ##If only Qwen3 has been uploaded, you only need to operate within this directory.1.3 Preparing the operating environment
Memory configuration (recommended) No need to modify the memory on PCIe, the following is related to the soc mode: For 1684X series devices (such as SE7/SM7), the environment preparation can be completed in this way to meet the Qwen2.5-VL operating conditions. First, make sure to use V24.04.01 SDK. You can check the SDK version through the bm_version command. If you need to upgrade, you can get the v24.04.01 version SDK from sophgo.com. The flash package is located in sophon-img-xxx/sdcard.tgz. Refer to the corresponding product manual for flashing.
After ensuring the SDK version, in the 1684x SoC environment, refer to the following command to modify the device memory:
cd /data/
mkdir memedit && cd memedit
wget -nd https://sophon-file.sophon.cn/sophon-prod-s3/drive/23/09/11/13/DeviceMemoryModificationKit.tgz
tar xvf DeviceMemoryModificationKit.tgz
cd DeviceMemoryModificationKit
tar xvf memory_edit_{vx.x}.tar.xz #vx.x is the version number
cd memory_edit
./memory_edit.sh -p #This command will print the current memory layout information
./memory_edit.sh -c -npu 7615 -vpu 2048 -vpp 2048 #If it is on the 1688 platform, please modify it to: ./memory_edit.sh -c -npu 10240 -vpu 0 -vpp 3072
sudo cp /data/memedit/DeviceMemoryModificationKit/memory_edit/emmcboot.itb /boot/emmcboot.itb && sync
sudo reboot1.4 Model Preparation
cd /data/Qwen3
# It is recommended to create a directory named Models/BM1684X under /data/Qwen3 and move the model to this directory (or you can skip creating the directory and just remember the model's path).
mkdir Models && mkdir Models/BM1684X && cd /data/Qwen3/Models/BM1684X
python3 -m dfss --url=open@sophgo.com:/ext_model_information/LLM/LLM-TPU/qwen3-4b_w4bf16_seq512_bm1684x_1dev_20250429_120231.bmodel ##Download the model file2. Python routine
2.1 Environmental Preparation
cd /data/Qwen3/python_demo
# It is recommended to create a text document named requirements.txt under /data/Qwen3/python_demo and add the following content:
transformers==4.49.0
torch==2.4.1
numpy==1.24.4
requests==2.32.3
torchvision==0.19.1
packaging==24.2
av==12.3.0
psutil==5.9.1
opencv-python-headless==4.11.0.86
# Additionally, you may need to install other libraries.
pip3 install dfss -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade
pip3 install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
# You need to install SILK2.Tools.logger.
python3 -m dfss --url=open@sophgo.com:tools/silk2/silk2.tools.logger-1.0.2-py3-none-any.whl
pip3 install silk2.tools.logger-1.0.2-py3-none-any.whl --force-reinstall
rm -f silk2.tools.logger-1.0.2-py3-none-any.whl
# This routine depends on sophon-sail. You can directly install sophon-sail by executing the following commands:
pip3 install dfss --upgrade
python3 -m dfss --install sail2.2 Compile and run the program
# Install the pybind11 development package
sudo apt-get update
sudo apt-get install pybind11-dev
mkdir build cd build && cmake .. && make && cp *cpython* .. && cd ..2.3 Running Tests
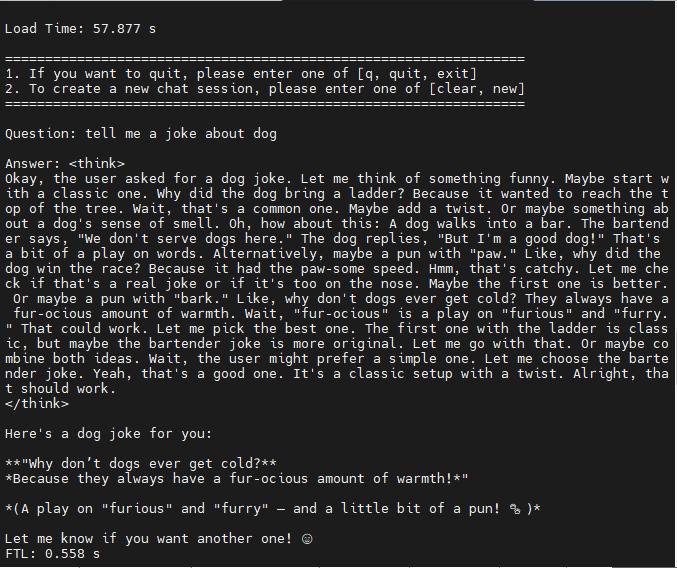
# chat test
python3 pipeline.py -m qwen3_xxx.bmodel -c config # Please replace the model path and config path with your own pathsEffects