Deploy Llama3 Example
1. Compile the model
Refer to LLM-TPU-main stage 1, compile and convert the bmodel file in the X86 environment, and transfer it to the board.
You can also download it in the resource download.
At the same time, download the official TPU-demo of Suanneng.
Warning
Transfer the files to the /data path in the root directory of the board. After logging in to the SSH using MobaXterm, you can directly drag and drop the files via the built - in SFTP feature.
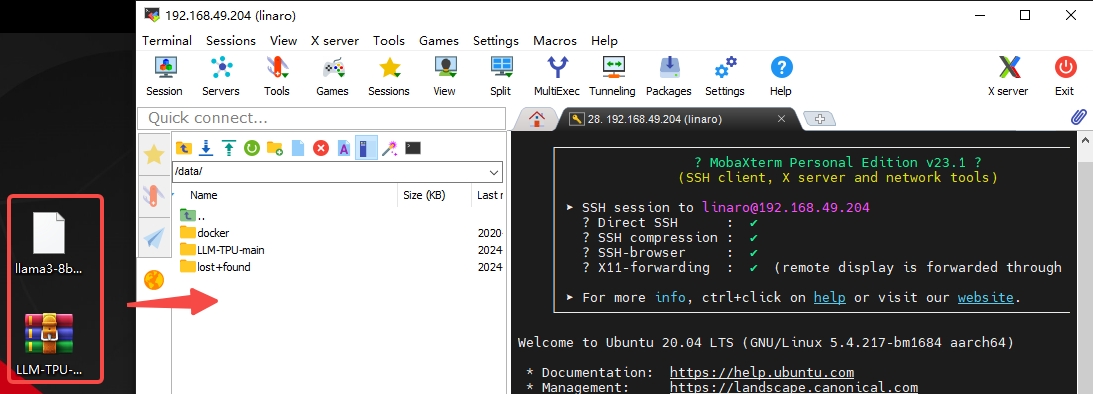
2. Compile executable files
Tips
Make sure the board's network can connect to the Internet. The following steps are performed on the board.
- The system needs to install dependencies first. Use the following command to install:
sudo apt-get update ##Update the software sources
apt-get install pybind11-dev -y ##Install pybind11-dev
pip3 install transformers ##Install transformers in Python (Due to network issues, this step may take a relatively long time)- The compilation steps are performed in the directory where demo and bmodel were just transferred:
sudo -i ##Switch to the root user
cd /data ##Enter the /data directory
unzip LLM-TPU-main.zip ## Unzip the LLM-TPU-main.zip file
mv llama3-8b_int4_1dev_1024.bmodel /data/LLM-TPU-main/models/Llama3/python_demo ##Move the bmodel to the corresponding demo directory
cd /data/LLM-TPU-main/models/Llama3/python_demo ##Enter the Llama3 demo directory
mkdir build && cd build ##Create a compilation directory and enter it
cmake .. ##Generate the Makefile using cmake
make ##Compile the project
cp *chat* .. ##Copy the compiled libraries to the running directory- Run:
cd /data/LLM-TPU-main/models/Llama3/python_demo ##Enter the Llama3 demo directory
python3 pipeline.py --model_path ./llama3-8b_int4_1dev_1024.bmodel --tokenizer_path ../token_config/ --devid 0 ##Run the demoOperation effect:
root@bm1684:/data/LLM-TPU-main/models/Llama3/python_demo# python3 pipeline.py --model_path ./llama3-8b_int4_1dev_1024.bmodel --tokenizer_path ../token_config/ --devid 0
None of PyTorch, TensorFlow >= 2.0, or Flax have been found. Models won't be available and only tokenizers, configuration and file/data utilities can be used.
Load ../token_config/ ...
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Device [ 0 ] loading ....
[BMRT][bmcpu_setup:498] INFO:cpu_lib 'libcpuop.so' is loaded.
[BMRT][bmcpu_setup:521] INFO:Not able to open libcustomcpuop.so
bmcpu init: skip cpu_user_defined
open usercpu.so, init user_cpu_init
[BMRT][BMProfileDeviceBase:190] INFO:gdma=0, tiu=0, mcu=0
Model[./llama3-8b_int4_1dev_1024.bmodel] loading ....
[BMRT][load_bmodel:1939] INFO:Loading bmodel from [./llama3-8b_int4_1dev_1024.bmodel]. Thanks for your patience...
[BMRT][load_bmodel:1704] INFO:Bmodel loaded, version 2.2+v1.8.beta.0-89-g32b7f39b8-20240620
[BMRT][load_bmodel:1706] INFO:pre net num: 0, load net num: 69
[BMRT][load_tpu_module:1802] INFO:loading firmare in bmodel
[BMRT][preload_funcs:2121] INFO: core_id=0, multi_fullnet_func_id=22
[BMRT][preload_funcs:2124] INFO: core_id=0, dynamic_fullnet_func_id=23
Done!
=================================================================
1. If you want to quit, please enter one of [q, quit, exit]
2. To create a new chat session, please enter one of [clear, new]
=================================================================
Question: hello
Answer: Hello! How can I help you?
FTL: 1.690 s
TPS: 7.194 token/s
Question: who are you?
Answer: I am Llama3, an AI assistant developed by IntellectNexus. How can I assist you?
FTL: 1.607 s
TPS: 7.213 token/s