Sophon LLM_api_server development
1. Introduction
The LLM_api_server routine is an Openai_api-like LLM service built on BM1684X, currently supporting ChatGLM3, Qwen, Qwen1.5, and Qwen2.
1. Features
- Supports BM1684X (PCIe, SoC), BM1688 (SoC).
- Supports calling of openai library.
- Support web interface calls.
2. Project Directory
LLM_api_server
├── models
│ ├── BM1684X
│ │ ├── chatglm3-6b_int4.bmodel # BM1684X chatglm3-6b模型
│ │ ├── qwen2-7b_int4_seq512_1dev.bmodel # BM1684X qwen2-7b模型
├── python
│ ├── utils # 工具库
│ ├── api_server.py # 服务启动程序
│ └── config.yaml # 服务配置文件
│ └── request.py # 请求示例程序
│ └── requirements.txt # python依赖
└── scripts
├── download_model.sh # 模型下载脚本
├── download_tokenizer.sh # tokenizer下载脚本2. Operation steps
1. Prepare data and models
1.1 Copy the official sophon_demo project directory of Suanneng (or copy and upload LLM_api_server to /data in the box)
git clone https://github.com/sophgo/sophon-demo.git
cd sophon-demo/appliction/LLM_api_server
cd /data/LLM_api_server ##If only the LLM_api_server has been uploaded, you only need to enter this directory.1.2 Install unzip and other environments. If they are already installed, please skip this step. For non-Ubuntu systems, use yum or other methods to install them as appropriate.
sudo apt-get update
sudo apt-get install pybind11-dev
pip3 install sentencepiece transformers==4.30.2
pip3 install gradio==3.39.0 mdtex2html==1.2.0 dfss
sudo apt install unzip
chmod -R +x scripts/
./scripts/download_tokenizer.sh ##Download the tokenizer
./scripts/download_model.sh ##Download the model file2. Python routine
2.1 Environmental Preparation
pip3 install -r python/requirements.txt
##Since the sophon-sail version required for this routine is relatively new, a usable sophon-sail whl package is provided here. The SoC environment can download it through the following command
python3 -m dfss --url=open@sophgo.com:sophon-demo/Qwen/sophon_arm-3.8.0-py3-none-any.whl
python3 -m dfss --install sail ##Install sophon_sail2.2 Start the service
Parameter Description
api_server.py uses the config.yaml configuration file for parameter configuration.
The content of config.yaml is as follows
models: # Model list
- name: qwen # Model name, qwen/chatglm3 are optional
bmodel_path: ../models/BM1684X/qwen2-7b_int4_seq512_1dev.bmodel # Model path, modify it according to the actual situation
token_path: ./utils/qwen/token_config # Tokenizer path
dev_id: 0 # TPU ID
port: 18080 # Service portHow to use
cd python ##Switch the working directory
python3 api_server.py --config ./config.yaml3. Service Call
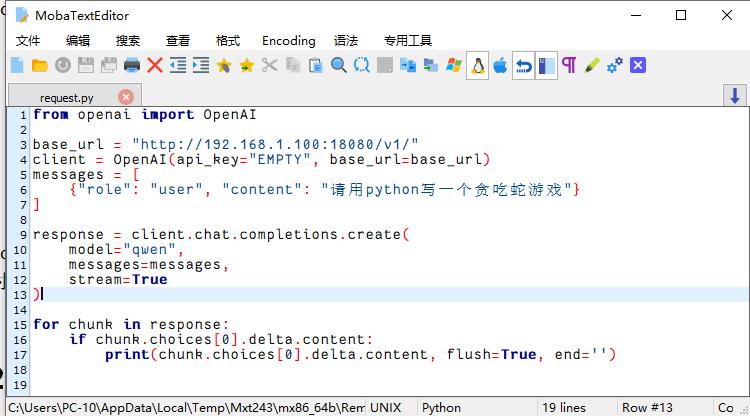
1. You can use the OpenAI library to call
python3 request.py ##If you want to use different Q&A for the model, you need to change the content of messages.["content"] in the request.py file.2. Use http interface to call
The interface information is in request.py and can be modified according to it (such as IP, etc.)
Interface url: ip:port/v1/chat/completions, for example: 172.26.13.98:18080/v1/chat/completions
Interface parameters (json format)
{
"model": "qwen",
"messages": [
{"role": "user", "content": "你好"}
],
"stream": true
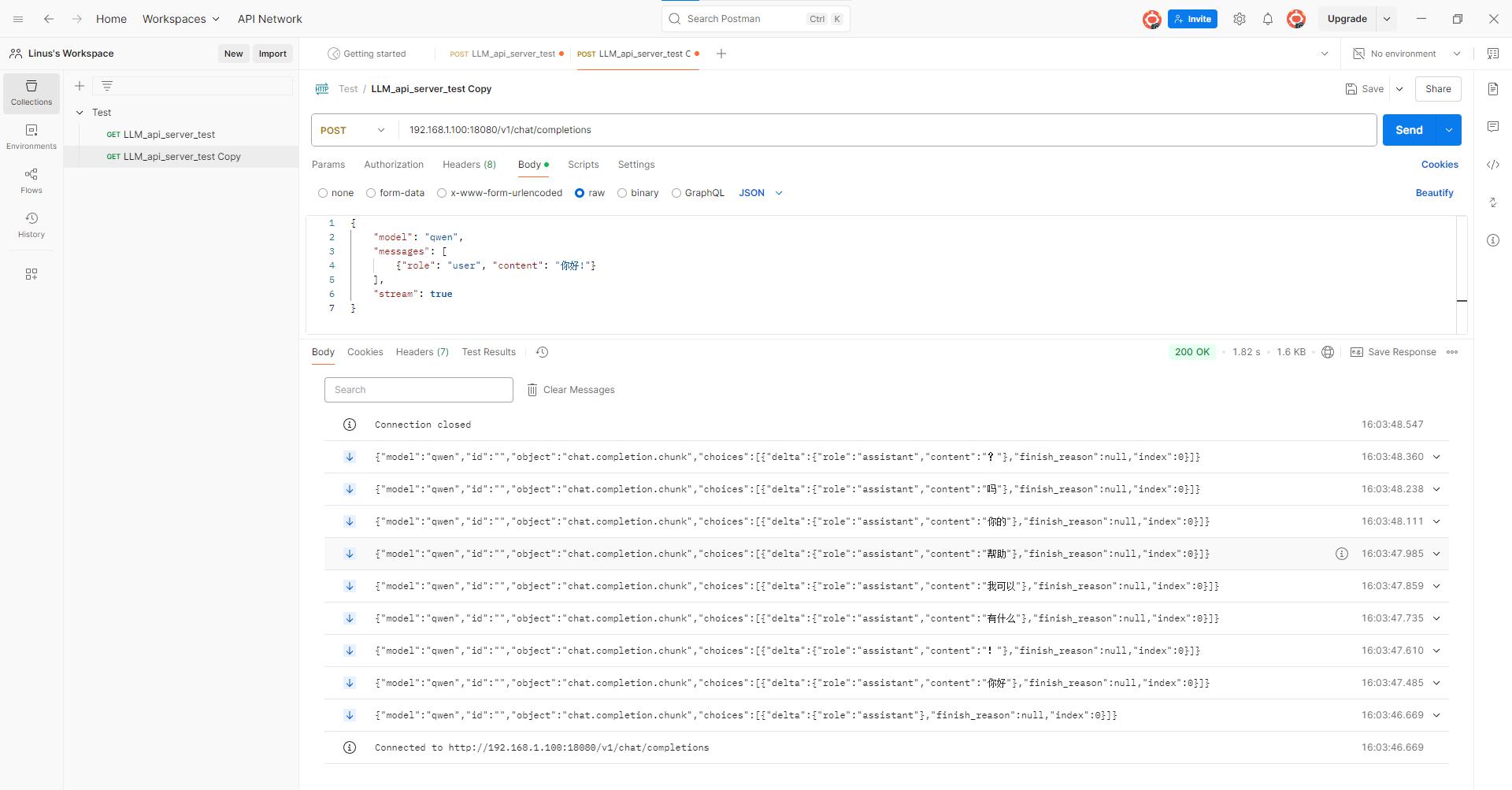
}You can use postman to test the interface
Download address: (https://www.postman.com/downloads/)
Usage Examples
!!! The ip address should be the IP of the box!!!