语音LLM应用 - 实验01-语音识别
实验准备:
1.安装 ALSA 工具(用于录音和播放)
sudo apt-get install alsa-utils
2.安装所需的依赖
1.pip install -r requirements.txt
2.python -m pip install websocket-client
3.sudo apt-get update && sudo apt-get install -y ffmpeg
3.注册讯飞账号
- 登录讯飞开放平台 https://www.xfyun.com.cn
- 点击进入控制台
- 注册登录账号
- 创建应用
- 开通语音识别-语音听写服务
- 获取APIID、APISecret、APIKey、语音听写接口地址四项信息
- 将四项信息保存(后续代码填入config.py中)
实验步骤:
- 检查使用语音模块 (确保语音模块与RDK主板以及喇叭已正确连接)
终端运行: arecord -l #识别麦克风的卡号与设备号(关注 card X 和 device Y )
终端运行: aplay -l #检查扬声器/输出设备
终端运行: sudo arecord -f S16\_LE -r 16000 -c 1 -d 5 /tmp/test\_mic.wav #使用默认设备录 5 秒,16k/单声道/16bit:
终端运行: aplay /tmp/test\_mic.wav #播放音频
- 将APIID、APISecret、APIKey、语音听写接口地址四项信息填入config.py
cd AI\_online\_voice#进入功能包python examples/01\_voice\_chat.py#运行示例程序 输入r 开始测试
终端运行效果如下:
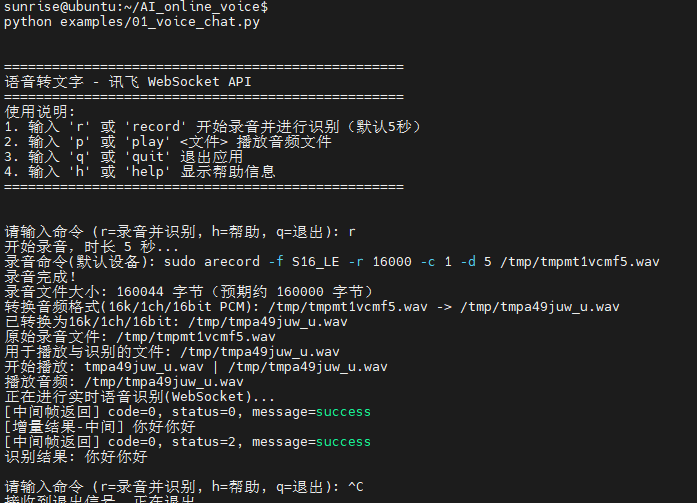
实验效果:开始录音(默认为5秒,如若需要修改时长,输入 r+时长 既可),录音完毕后播放音频,随后将音频上传讯飞语音听写大模型,最后将识别结果返回Linux终端)
"""
01_voice_chat.py
功能:
- 录制语音
- 使用讯飞 WebSocket API 将语音转为文本
- 在终端打印识别结果(专注于语音转文字)
依赖:
- arecord: 用于录制音频(Linux)
- aplay: 用于播放音频(Linux)
- websocket-client: 用于与讯飞 WebSocket API 通信
- 请在 AI_online_voice/config.py 中填写 XUNFEI_APPID / XUNFEI_API_KEY / XUNFEI_API_SECRET / XUNFEI_WS_URL
"""
import os
import sys
import time
from typing import Optional
# 加入父目录,便于示例脚本直接运行
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
# 仅保留音频处理,暂不使用豆包对话
from utils.audio_processor import AudioProcessor
# 讯飞 WebSocket 所需依赖与配置
try:
import websocket # websocket-client
except ImportError:
websocket = None
# 新增:导入超时异常类型用于精细日志
try:
from websocket import WebSocketTimeoutException
except Exception:
class WebSocketTimeoutException(Exception):
pass
import json
import base64
import hmac
import hashlib
import ssl
import wave
from email.utils import formatdate
from urllib.parse import urlparse, quote
from config import (
XUNFEI_APPID,
XUNFEI_API_KEY,
XUNFEI_API_SECRET,
XUNFEI_WS_URL,
REQUEST_TIMEOUT,
)
class XunfeiRealtimeSpeechClient:
"""讯飞语音识别(IAT流式WebSocket版)客户端(更新的消息格式与解析)"""
def __init__(self, app_id: str = None, api_key: str = None, api_secret: str = None, ws_url: str = None):
self.app_id = app_id or XUNFEI_APPID
self.api_key = api_key or XUNFEI_API_KEY
self.api_secret = api_secret or XUNFEI_API_SECRET
self.ws_url = ws_url or XUNFEI_WS_URL
self.timeout = REQUEST_TIMEOUT
self._validate_config()
def _validate_config(self):
if not self.app_id or self.app_id == "你的讯飞APPID":
raise ValueError("请配置正确的讯飞APPID")
if not self.api_key or self.api_key == "你的讯飞API_KEY":
raise ValueError("请配置正确的讯飞API_KEY")
if not self.api_secret or self.api_secret == "你的讯飞API_SECRET":
raise ValueError("请配置正确的讯飞API_SECRET")
if websocket is None:
raise RuntimeError("未安装 websocket-client,请先安装:python -m pip install websocket-client")
def _rfc1123_date(self) -> str:
# 生成GMT时间,RFC1123格式
return formatdate(usegmt=True)
def _assemble_auth_url(self) -> str:
"""根据APIKey与APISecret生成带鉴权参数的WS URL"""
parsed = urlparse(self.ws_url)
host = parsed.netloc
path = parsed.path
date = self._rfc1123_date()
# signature 原始串:
signature_origin = f"host: {host}\n" + f"date: {date}\n" + f"GET {path} HTTP/1.1"
# 使用 apiSecret 做 HMAC-SHA256
signature_sha = hmac.new(self.api_secret.encode("utf-8"), signature_origin.encode("utf-8"), hashlib.sha256).digest()
signature = base64.b64encode(signature_sha).decode("utf-8")
# authorization 原始串
authorization_origin = (
f"api_key=\"{self.api_key}\", "
f"algorithm=\"hmac-sha256\", "
f"headers=\"host date request-line\", "
f"signature=\"{signature}\""
)
authorization = base64.b64encode(authorization_origin.encode("utf-8")).decode("utf-8")
# 拼接最终URL
auth_url = (
f"{self.ws_url}?authorization={quote(authorization)}&date={quote(date)}&host={quote(host)}"
)
return auth_url
def _parse_result_segments(self, result_obj: dict) -> str:
"""解析服务端 data.result.ws 结构为纯文本"""
try:
parts = []
ws_arr = result_obj.get("ws")
if isinstance(ws_arr, list):
for ws in ws_arr:
cw_arr = ws.get("cw") if isinstance(ws, dict) else None
if isinstance(cw_arr, list):
for cw in cw_arr:
w = cw.get("w") if isinstance(cw, dict) else None
if w:
parts.append(w)
return "".join(parts)
except Exception:
return ""
def _safe_json_loads(self, text: str):
try:
return json.loads(text)
except Exception:
try:
cleaned = text.strip()
start = cleaned.find("{")
end = cleaned.rfind("}")
if start != -1 and end != -1 and end > start:
return json.loads(cleaned[start:end+1])
except Exception:
return None
def transcribe_audio_ws(self, audio_file: str) -> Optional[str]:
"""将音频文件以流式方式发送到讯飞IAT WS接口并获取识别文本"""
if not os.path.exists(audio_file):
print(f"音频文件不存在: {audio_file}")
return None
# 解析wav
try:
wf = wave.open(audio_file, "rb")
except Exception as e:
print(f"打开音频文件失败: {e}")
return None
framerate = wf.getframerate()
channels = wf.getnchannels()
sampwidth = wf.getsampwidth() # bytes per sample
# 建议参数:16k, 单声道, 16bit
if framerate not in (8000, 16000):
print(f"采样率异常({framerate}),建议使用16k或8k")
if channels != 1:
print(f"通道数为{channels},建议使用单声道")
if sampwidth != 2:
print(f"位深为{sampwidth*8}bit,建议16bit")
auth_url = self._assemble_auth_url()
ws = None
try:
ws = websocket.create_connection(
auth_url,
timeout=self.timeout,
sslopt={"cert_reqs": ssl.CERT_NONE},
)
ws.settimeout(self.timeout)
# 计算每帧40ms对应的帧数
frames_per_chunk = max(1, int(framerate * 0.04))
# 构建格式字符串,例如 audio/L16;rate=16000;channel=1
fmt = f"audio/L{sampwidth*8};rate={framerate};channel={channels}"
# 初始化增量聚合与最终状态标记
final_text_parts = []
saw_final_status = False
# 发送首帧(status=0)
first_chunk = wf.readframes(frames_per_chunk)
first_payload = base64.b64encode(first_chunk).decode("utf-8") if first_chunk else ""
first_frame = {
"common": {"app_id": self.app_id},
"business": {
"domain": "iat",
"language": "zh_cn",
"accent": "mandarin",
"vinfo": 1,
"vad_eos": 2000,
"ptt": 0,
},
"data": {
"status": 0,
"format": fmt,
"encoding": "raw",
"audio": first_payload,
},
}
try:
ws.send(json.dumps(first_frame, separators=(",", ":")))
except Exception as e:
print(f"发送首帧失败: {e}")
print("可能原因:鉴权失败或 WS URL 错误导致服务端立即关闭连接")
return None
# 增强:首帧后循环尝试接收,打印并积累增量结果
try:
ws.settimeout(1.0)
for _ in range(3):
try:
pre_resp_text = ws.recv()
except WebSocketTimeoutException:
break
if not pre_resp_text:
break
pre_resp = self._safe_json_loads(pre_resp_text)
if not pre_resp:
print(f"[首帧返回-非JSON] {pre_resp_text}")
break
code = pre_resp.get("code")
message = pre_resp.get("message")
if code is None:
header = pre_resp.get("header", {})
code = header.get("code", 0)
message = header.get("message")
data = pre_resp.get("data", {})
status = data.get("status")
print(f"[首帧返回] code={code}, status={status}, message={message}")
if code != 0:
desc = message or "识别错误"
print(f"识别错误(连接初期): code={code}, message={desc}")
return None
result = data.get("result")
if result:
segment = self._parse_result_segments(result)
if segment:
final_text_parts.append(segment)
print(f"[增量结果-首帧] {segment}")
if status == 2:
saw_final_status = True
break
except Exception as e:
print(f"[首帧接收日志] {e}")
finally:
ws.settimeout(self.timeout)
# 发送中间帧(status=1)
while True:
chunk = wf.readframes(frames_per_chunk)
if not chunk or saw_final_status:
break
frame = {
"common": {"app_id": self.app_id},
"data": {
"status": 1,
"format": fmt,
"encoding": "raw",
"audio": base64.b64encode(chunk).decode("utf-8"),
},
}
try:
ws.send(json.dumps(frame, separators=(",", ":")))
except Exception as e:
print(f"发送中间帧失败: {e}")
print("可能原因:连接已被服务端关闭(鉴权/配置错误、URL错误、参数不匹配)")
return None
# 每次发送后短暂接收,积累增量结果
try:
ws.settimeout(0.5)
resp_text_mid = ws.recv()
if resp_text_mid:
resp_mid = self._safe_json_loads(resp_text_mid)
if not resp_mid:
print(f"[中间帧返回-非JSON] {resp_text_mid}")
else:
code_mid = resp_mid.get("code")
msg_mid = resp_mid.get("message")
if code_mid is None:
header_mid = resp_mid.get("header", {})
code_mid = header_mid.get("code", 0)
msg_mid = header_mid.get("message")
data_mid = resp_mid.get("data", {})
status_mid = data_mid.get("status")
print(f"[中间帧返回] code={code_mid}, status={status_mid}, message={msg_mid}")
if code_mid != 0:
print(f"识别错误(发送中间帧后): code={code_mid}, message={msg_mid}")
return None
result_mid = data_mid.get("result")
if result_mid:
seg_mid = self._parse_result_segments(result_mid)
if seg_mid:
final_text_parts.append(seg_mid)
print(f"[增量结果-中间] {seg_mid}")
if status_mid == 2:
saw_final_status = True
break
except WebSocketTimeoutException:
pass
except Exception as e:
print(f"接收中间帧返回失败: {e}")
return None
finally:
ws.settimeout(self.timeout)
time.sleep(0.04)
# 若尚未收到最终状态,发送结束帧
if not saw_final_status:
last_frame = {
"common": {"app_id": self.app_id},
"data": {
"status": 2,
"format": fmt,
"encoding": "raw",
"audio": "",
},
}
try:
ws.send(json.dumps(last_frame, separators=(",", ":")))
except Exception as e:
print(f"发送结束帧失败: {e}")
# 即使结束帧发送失败,只要已有增量文本也返回
return "".join(final_text_parts) if final_text_parts else None
# 接收最终结果(容错:超时但已有增量文本则直接返回)
if not saw_final_status:
while True:
try:
resp_text = ws.recv()
except Exception as e:
print(f"接收结果失败: {e}")
return "".join(final_text_parts) if final_text_parts else None
if not resp_text:
continue
resp = self._safe_json_loads(resp_text)
if not resp:
continue
code = resp.get("code")
message = resp.get("message")
if code is None:
header = resp.get("header", {})
code = header.get("code", 0)
message = header.get("message")
if code != 0:
desc = message or "识别错误"
print(f"识别错误: code={code}, message={desc}")
break
data = resp.get("data", {})
status = data.get("status")
result = resp.get("result") or data.get("result")
if result:
segment = self._parse_result_segments(result)
if segment:
final_text_parts.append(segment)
if status == 2:
break
return "".join(final_text_parts) if final_text_parts else None
finally:
try:
wf.close()
except Exception:
pass
if ws is not None:
try:
ws.close()
except Exception:
pass
class VoiceChatApp:
"""语音对话应用(仅语音转文字与打印)"""
def __init__(self):
"""初始化应用"""
self.processor = None
self.xunfei_ws_client = None
self.running = False
def initialize(self) -> bool:
"""初始化客户端和处理器"""
try:
self.processor = AudioProcessor()
self.xunfei_ws_client = XunfeiRealtimeSpeechClient()
return True
except Exception as e:
print(f"初始化失败: {e}")
return False
def print_welcome(self):
"""打印欢迎信息"""
print("\n" + "=" * 50)
print("语音转文字 - 讯飞 WebSocket API")
print("=" * 50)
print("使用说明:")
print("1. 输入 'r' 或 'record' 开始录音并进行识别(默认5秒)")
print("2. 输入 'p' 或 'play' <文件> 播放音频文件")
print("3. 输入 'q' 或 'quit' 退出应用")
print("4. 输入 'h' 或 'help' 显示帮助信息")
print("=" * 50 + "\n")
def print_help(self):
"""打印帮助信息"""
print("\n" + "=" * 50)
print("命令列表:")
print(" r, record [秒数] - 录制语音 (默认5秒) 并用WebSocket识别,终端打印文本")
print(" p, play <文件> - 播放音频文件")
print(" q, quit - 退出应用")
print(" h, help - 显示帮助信息")
print("=" * 50 + "\n")
def handle_command(self, command: str) -> bool:
"""处理命令"""
parts = command.strip().split()
if not parts:
return True
cmd = parts[0].lower()
if cmd in ('q', 'quit', 'exit'):
return False
elif cmd in ('h', 'help'):
self.print_help()
elif cmd in ('r', 'record'):
# 解析录音时长
duration = 5
if len(parts) > 1:
try:
duration = int(parts[1])
except ValueError:
print("无效的时长,使用默认值5秒")
# 录制音频
audio_file = self.processor.record(duration)
if not audio_file:
print("录音失败")
return True
# 新增:录音后强制转换为 16k/1ch/16bit PCM WAV
converted_file = self.processor.convert_to_wav(audio_file)
use_file = converted_file or audio_file
if converted_file:
print(f"已转换为16k/1ch/16bit: {converted_file}")
else:
print("转换失败,使用原始录音进行识别")
# 新增:打印文件名与完整路径,并先播放音频
try:
import os
file_name = os.path.basename(use_file)
print(f"原始录音文件: {audio_file}")
print(f"用于播放与识别的文件: {use_file}")
print(f"开始播放: {file_name} | {use_file}")
play_ok = self.processor.play(use_file)
if not play_ok:
print("播放失败,但继续进行识别")
except Exception as e:
print(f"播放流程异常: {e},继续进行识别")
# 使用讯飞WS实时识别
print("正在进行实时语音识别(WebSocket)...")
text = self.xunfei_ws_client.transcribe_audio_ws(use_file)
if text:
print(f"识别结果: {text}")
else:
print("语音识别失败")
elif cmd in ('p', 'play'):
if len(parts) < 2:
print("请指定要播放的音频文件")
return True
audio_file = parts[1]
self.processor.play(audio_file)
else:
print(f"未知命令: {cmd}")
print("输入 'h' 或 'help' 获取帮助")
return True
def run(self):
"""运行应用"""
if not self.initialize():
print("应用初始化失败,请检查配置")
return
self.print_welcome()
self.running = True
while self.running:
try:
command = input("\n请输入命令 (r=录音并识别, h=帮助, q=退出): ")
self.running = self.handle_command(command)
except KeyboardInterrupt:
print("\n接收到退出信号,正在退出...")
self.running = False
except Exception as e:
print(f"发生错误: {e}")
print("应用已退出")
def main():
"""主函数"""
app = VoiceChatApp()
app.run()
if __name__ == "__main__":
main()