AI在线开发
实验03-多模态视觉分析定位
实验准备:
- 确保已接入火山引擎豆包ai
- 寻找图片,作为实验素材
实验步骤:
cd AI_online#进入主目录python examples/02_image_chat.py#运行示例程序
(如若出现报错信息: (unicode error) 'utf-8' codec can't decode byte 0xcf in position 3: invalid continuation byte 。请运行命令,把源文件转为UTF-8编码:iconv -f GBK -t UTF-8 examples/02_image_chat.py -o /tmp/02_image_chat.py && mv /tmp/02_image_chat.py examples/02_image_chat.py )
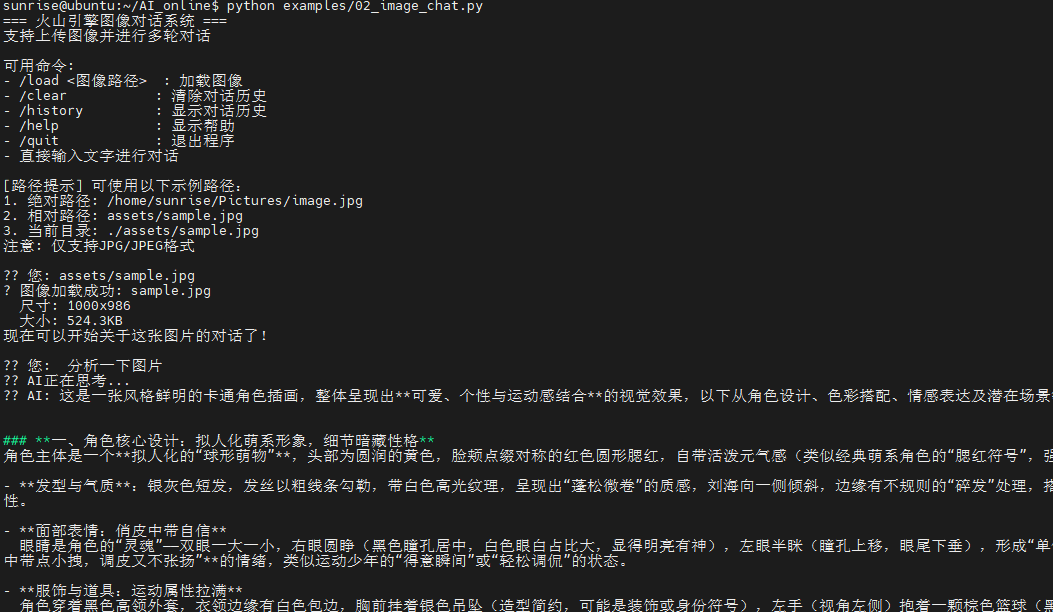
终端打印如下:
# -*- coding: utf-8 -*-
"""
多模态对话示例
集成文本和图像的完整对话系统
"""
import os
import sys
from typing import List, Dict, Optional
# 添加父目录到路径
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from utils.api_client import DoubaoAPIClient
from utils.image_processor import ImageProcessor
class MultimodalChatSystem:
"""多模态对话系统"""
def __init__(self):
"""初始化系统"""
try:
self.client = DoubaoAPIClient()
self.processor = ImageProcessor()
self.chat_history: List[Dict] = []
self.system_prompt = "你是一个智能的AI助手,能够理解和分析图像内容,并与用户进行自然对话。"
print("多模态对话系统初始化成功")
except Exception as e:
print(f"系统初始化失败: {e}")
raise
def add_system_message(self, prompt: str):
"""设置系统提示词"""
self.system_prompt = prompt
print(f"系统提示词已更新")
def send_text_message(self, message: str) -> Optional[str]:
"""
发送纯文本消息
Args:
message: 用户消息
Returns:
str: AI回复
"""
try:
# 复刻实验01的调用方式:仅包含系统提示词与当前用户消息
response = self.client.chat_text(message, system_prompt=self.system_prompt)
if response:
# 更新历史
self.chat_history.append({"role": "user", "content": message})
self.chat_history.append({"role": "assistant", "content": response})
return response
return None
except Exception as e:
print(f"发送文本消息失败: {e}")
return None
def send_image_message(self, text: str, image_path: str) -> Optional[str]:
"""
发送图文消息
Args:
text: 文本内容
image_path: 图像路径
Returns:
str: AI回复
"""
try:
# 放宽校验,支持 JPG/JPEG/PNG
if not os.path.exists(image_path):
print(f"图像文件不存在: {image_path}")
return None
if not image_path.lower().endswith((".jpg", ".jpeg", ".png")):
print("仅支持JPG/JPEG/PNG格式,请使用 .jpg/.jpeg/.png 文件")
return None
# 获取图像信息
image_info = self.processor.get_image_info(image_path)
print(f"处理图像: {os.path.basename(image_path)} ({image_info.get('width')}x{image_info.get('height')})")
# 复刻实验02的调用方式:直接通过客户端封装发送图像文件
response = self.client.chat_with_image_file(text, image_path, system_prompt=self.system_prompt)
if response:
# 更新历史(简化存储,只保存文本部分)
self.chat_history.append({
"role": "user",
"content": f"{text} [图像: {os.path.basename(image_path)}]"
})
self.chat_history.append({"role": "assistant", "content": response})
return response
return None
except Exception as e:
print(f"发送图文消息失败: {e}")
return None
def analyze_image_detailed(self, image_path: str, analysis_focus: str = None) -> Optional[str]:
"""
详细分析图像
Args:
image_path: 图像路径
analysis_focus: 分析重点
Returns:
str: 分析结果
"""
if analysis_focus:
prompt = f"请重点分析这张图片的{analysis_focus},并提供详细描述。"
else:
prompt = "请详细分析这张图片,包括内容、构图、色彩、情感等各个方面。"
return self.send_image_message(prompt, image_path)
def compare_images(self, image1_path: str, image2_path: str, comparison_aspect: str = None) -> Optional[str]:
"""
比较两张图像(需要分别分析后总结)
Args:
image1_path: 第一张图像路径
image2_path: 第二张图像路径
comparison_aspect: 比较方面
Returns:
str: 比较结果
"""
try:
# 分析第一张图像
print("分析第一张图像...")
result1 = self.analyze_image_detailed(image1_path, "整体内容和特征")
if not result1:
return None
# 分析第二张图像
print("分析第二张图像...")
result2 = self.analyze_image_detailed(image2_path, "整体内容和特征")
if not result2:
return None
# 生成比较总结(将两次分析内容纳入同一次请求上下文)
if comparison_aspect:
compare_task = f"请重点比较它们在{comparison_aspect}方面的异同。"
else:
compare_task = "请总结比较这两张图片的异同点。"
comparison_prompt = (
"以下是两张图片的分析,请基于这些分析进行比较:\n"
"【图片1分析】\n"
f"{result1}\n\n"
"【图片2分析】\n"
f"{result2}\n\n"
f"{compare_task}"
)
comparison_result = self.send_text_message(comparison_prompt)
return comparison_result
except Exception as e:
print(f"图像比较失败: {e}")
return None
def clear_history(self):
"""清除对话历史"""
self.chat_history = []
print("对话历史已清除")
def show_history(self):
"""显示对话历史"""
if not self.chat_history:
print("暂无对话历史")
return
print("\n=== 对话历史 ===")
for i, msg in enumerate(self.chat_history, 1):
role = "用户" if msg["role"] == "user" else "AI"
content = msg["content"]
print(f"{i}. {role}: {content}")
print("=" * 50)
def get_stats(self) -> Dict:
"""获取统计信息"""
return {
"total_messages": len(self.chat_history),
"user_messages": len([m for m in self.chat_history if m["role"] == "user"]),
"ai_messages": len([m for m in self.chat_history if m["role"] == "assistant"]),
"system_prompt": self.system_prompt[:50] + "..." if len(self.system_prompt) > 50 else self.system_prompt
}
def main():
"""主函数"""
print("=== 多模态AI对话系统 ===")
print("支持文本对话、图像分析、图文结合等功能")
try:
# 初始化系统
chat_system = MultimodalChatSystem()
print("\n可用功能:")
print("1. 文本对话 - 直接输入文字")
print("2. 图像分析 - /analyze <图像路径> [分析重点]")
print("3. 图文对话 - /image <图像路径> <问题>")
print("4. 图像比较 - /compare <图像1> <图像2> [比较方面]")
print("5. 系统设置 - /system <提示词>")
print("6. 查看历史 - /history")
print("7. 清除历史 - /clear")
print("8. 统计信息 - /stats")
print("9. 帮助信息 - /help")
print("10. 退出程序 - /quit")
# 路径规范化与解析(项目根优先,其次当前目录;支持 ~ 展开;在非 Windows 自动将反斜杠转为斜杠)
def normalize_and_resolve(p: str) -> str:
p = p.strip().strip('"').strip("'")
p = os.path.expanduser(p)
if os.name != 'nt':
p = p.replace('\\', '/')
project_root = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
candidate = os.path.join(project_root, p) if not os.path.isabs(p) else p
if not os.path.isabs(p):
if os.path.exists(candidate):
return candidate
elif os.path.exists(p):
return p
else:
return p
else:
return p
while True:
try:
user_input = input("\n您: ").strip()
if not user_input:
continue
# 处理命令
first_token = user_input.split(" ", 1)[0].lower()
recognized_commands = {"/analyze", "/image", "/compare", "/system", "/history", "/clear", "/stats", "/help", "/quit"}
if user_input.startswith("/") and first_token in recognized_commands:
parts = user_input.split(" ", 2)
command = parts[0].lower()
if command == "/quit":
print("感谢使用多模态AI对话系统!")
break
elif command == "/help":
print("\n可用功能:")
print("1. 文本对话 - 直接输入文字")
print("2. 图像分析 - /analyze <图像路径> [分析重点]")
print("3. 图文对话 - /image <图像路径> <问题>")
print("4. 图像比较 - /compare <图像1> <图像2> [比较方面]")
print("5. 系统设置 - /system <提示词>")
print("6. 查看历史 - /history")
print("7. 清除历史 - /clear")
print("8. 统计信息 - /stats")
print("9. 退出程序 - /quit")
if os.name == 'nt':
print("\n[路径提示] 示例:")
print("- 绝对路径: C:\\Users\\Administrator\\Pictures\\a.jpg")
print("- 相对路径: assets\\sample.jpg")
print("- 当前目录: .\\assets\\sample.jpg")
else:
print("\n[路径提示] 示例:")
print("- 绝对路径: /home/user/Pictures/a.jpg")
print("- 相对路径: assets/sample.jpg")
print("- 当前目录: ./assets/sample.jpg")
print("注意: 支持 JPG/JPEG/PNG 格式")
elif command == "/clear":
chat_system.clear_history()
elif command == "/history":
chat_system.show_history()
elif command == "/stats":
stats = chat_system.get_stats()
print(f"\n统计信息:")
print(f"总消息数: {stats['total_messages']}")
print(f"用户消息: {stats['user_messages']}")
print(f"AI回复: {stats['ai_messages']}")
print(f"系统提示: {stats['system_prompt']}")
elif command == "/system":
if len(parts) < 2:
print("请提供系统提示词: /system <提示词>")
continue
new_prompt = " ".join(parts[1:])
chat_system.add_system_message(new_prompt)
elif command == "/analyze":
if len(parts) < 2:
print("请提供图像路径: /analyze <图像路径> [分析重点]")
continue
image_path = parts[1]
analysis_focus = parts[2] if len(parts) > 2 else None
resolved = normalize_and_resolve(image_path)
if not os.path.exists(resolved):
print(f"图像文件不存在: {resolved}")
continue
if not resolved.lower().endswith((".jpg", ".jpeg", ".png")):
print("仅支持JPG/JPEG/PNG格式,请使用 .jpg/.jpeg/.png 文件")
continue
print("正在分析图像...")
result = chat_system.analyze_image_detailed(resolved, analysis_focus)
if result:
print(f"分析结果: {result}")
else:
print("图像分析失败")
elif command == "/image":
if len(parts) < 3:
print("请提供图像路径和问题: /image <图像路径> <问题>")
continue
image_path = parts[1]
question = parts[2]
resolved = normalize_and_resolve(image_path)
if not os.path.exists(resolved):
print(f"图像文件不存在: {resolved}")
continue
if not resolved.lower().endswith((".jpg", ".jpeg", ".png")):
print("仅支持JPG/JPEG/PNG格式,请使用 .jpg/.jpeg/.png 文件")
continue
print("正在处理图文对话...")
result = chat_system.send_image_message(question, resolved)
if result:
print(f"AI: {result}")
else:
print("图文对话失败")
elif command == "/compare":
if len(parts) < 3:
print("请提供两个图像路径: /compare <图像1> <图像2> [比较方面]")
continue
image1 = parts[1]
image2_and_aspect = parts[2].split(" ", 1)
image2 = image2_and_aspect[0]
aspect = image2_and_aspect[1] if len(image2_and_aspect) > 1 else None
image1 = normalize_and_resolve(image1)
image2 = normalize_and_resolve(image2)
if not os.path.exists(image1):
print(f"第一张图像不存在: {image1}")
continue
if not os.path.exists(image2):
print(f"第二张图像不存在: {image2}")
continue
if (not image1.lower().endswith((".jpg", ".jpeg", ".png"))) or (not image2.lower().endswith((".jpg", ".jpeg", ".png"))):
print("仅支持JPG/JPEG/PNG格式,请使用 .jpg/.jpeg/.png 文件")
continue
print("正在比较图像...")
result = chat_system.compare_images(image1, image2, aspect)
if result:
print(f"比较结果: {result}")
else:
print("图像比较失败")
elif user_input.startswith("/"):
print("未知命令,输入 /help 查看帮助")
else:
# 普通文本对话或直接路径输入(支持 ~、非 Windows 下反斜杠自动转换)
use_path = normalize_and_resolve(user_input)
if os.path.exists(use_path) and use_path.lower().endswith((".jpg", ".jpeg", ".png")):
print("检测到路径输入,执行图像详细分析...")
result = chat_system.analyze_image_detailed(use_path)
if result:
print(f"分析结果: {result}")
else:
print("图像分析失败")
continue
print("正在思考...")
response = chat_system.send_text_message(user_input)
if response:
print(f"AI: {response}")
else:
print("获取回复失败,请重试")
except KeyboardInterrupt:
print("\n\n程序被用户中断")
break
except Exception as e:
print(f"发生错误: {e}")
except Exception as e:
print(f"系统启动失败: {e}")
print("请检查config.py中的API配置")
if __name__ == "__main__":
main()