语音LLM应用 - 实验05-多模态文档分析-语音对话
实验准备:
- 确保已接入火山引擎豆包AI以及讯飞AI(参考实验01、实验02)
- 寻找文档,作为实验素材。文档导入分为相对路径以及绝对路径,相对路径默认设置为AI_online_voice/assets/text.docx (功能包中已添加了默认的相对路径文档,可更改相对路劲文档,但命名需为text.docx )
- 下载相关依赖(若已下载可自动忽略)
(1) pip install python-docx
(2) pip install openpyxl
实验步骤:(确保语音模块已连接)
cd AI_online_voice#进入主目录python examples/05_voice_document_analysis.py#运行示例程序- 进入程序后根据终端提示,先输入y,进入文档选择,可语音选择绝对路径以及相对路径,绝对路径手动输入文档路劲,相对路劲默认设置为assets/text.docx 。
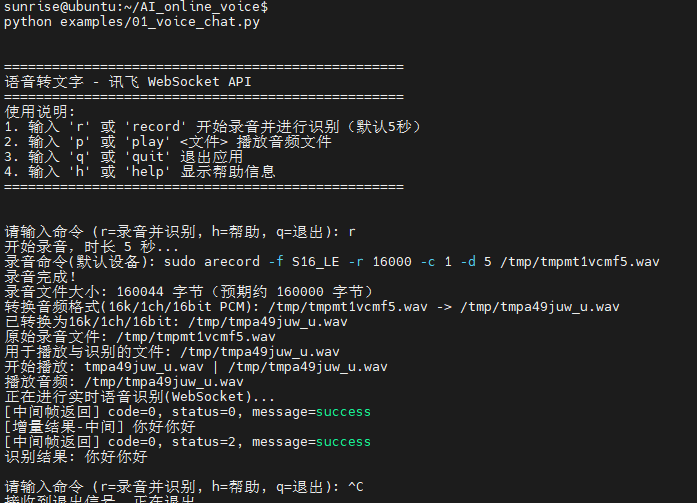
终端运行结果示例:
# -*- coding: utf-8 -*-
"""
05_voice_document_analysis.py
实验05:文档分析 - 语音
- 参考实验03的语音选择方式与运行逻辑
- 文档导入分为绝对路径与相对路径:
- 绝对路径:用户手动输入
- 相对路径:默认 /home/sunrise/AI_online_voice/assets/text.docx(若不存在则回退为项目根下 assets/text.docx)
- 支持文档类型:Word(.docx)与 Excel(.xlsx)
指令:
- i:选择并导入文档(语音选择绝对/相对路径)
- r [秒数]:录音并提交到豆包进行文档分析(默认5秒)
- p:回放最近一次录音
- h:帮助
- q:退出
"""
import os
import sys
import wave
import base64
from typing import Optional
import importlib.util
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
PROJECT_ROOT = os.path.dirname(CURRENT_DIR)
sys.path.append(PROJECT_ROOT)
from utils.audio_processor import AudioProcessor
import config
# 动态导入实验03模块,复用内联客户端(讯飞 WS 与豆包)
EXP03_PATH = os.path.join(PROJECT_ROOT, "examples", "03_voice_image_dialogue.py")
spec = importlib.util.spec_from_file_location("exp03", EXP03_PATH)
exp03 = importlib.util.module_from_spec(spec)
spec.loader.exec_module(exp03)
DoubaoAPIClient = exp03.DoubaoAPIClient
XunfeiRealtimeSpeechClient = exp03.XunfeiRealtimeSpeechClient
ROOT_CONFIG = getattr(exp03, "ROOT_CONFIG", None)
class DocumentLoader:
"""解析文档为纯文本。支持 .docx 与 .xlsx。
- 对 .docx:提取段落文本。
- 对 .xlsx:提取前几个工作表的前若干行,合并为文本。
- 对大文档进行截断,避免请求过长。
"""
def __init__(self, max_chars: int = 8000):
self.max_chars = max_chars
def load_text(self, path: str) -> Optional[str]:
if not path or not os.path.exists(path):
return None
ext = os.path.splitext(path)[1].lower()
try:
if ext == ".docx":
return self._load_docx(path)
elif ext == ".xlsx":
return self._load_xlsx(path)
else:
print("[文档] 当前仅支持 .docx 与 .xlsx")
return None
except Exception as e:
print(f"[文档] 解析失败: {e}")
return None
def _truncate(self, text: str) -> str:
if text and len(text) > self.max_chars:
return text[: self.max_chars] + "\n[...内容截断...]"
return text
def _load_docx(self, path: str) -> str:
try:
import docx # python-docx
except Exception:
print("[依赖缺失] 未安装 python-docx,请先安装:pip install python-docx")
raise
doc = docx.Document(path)
parts = []
for p in doc.paragraphs:
txt = (p.text or "").strip()
if txt:
parts.append(txt)
text = "\n".join(parts)
return self._truncate(text)
def _load_xlsx(self, path: str) -> str:
try:
import openpyxl
except Exception:
print("[依赖缺失] 未安装 openpyxl,请先安装:pip install openpyxl")
raise
wb = openpyxl.load_workbook(path, read_only=True, data_only=True)
parts = []
sheet_limit = 3
row_limit = 100
for si, sheet in enumerate(wb.worksheets):
if si >= sheet_limit:
break
parts.append(f"[Sheet] {sheet.title}")
rows = sheet.iter_rows(min_row=1, max_row=row_limit, values_only=True)
for row in rows:
vals = [str(v) if v is not None else "" for v in row]
line = "\t".join(vals).strip()
if line:
parts.append(line)
text = "\n".join(parts)
return self._truncate(text)
class VoiceDocumentAnalysisApp:
def __init__(self):
self.processor = AudioProcessor()
self.asr = XunfeiRealtimeSpeechClient()
self.doubao = DoubaoAPIClient()
self.loader = DocumentLoader()
self.last_audio: Optional[str] = None
self.last_wav: Optional[str] = None
self.doc_path: Optional[str] = None
def _resolve_path(self, p: str, is_absolute: bool = False) -> Optional[str]:
if not p:
return None
p = os.path.expanduser(p)
if os.name != "nt":
p = p.replace("\\", "/")
if is_absolute or os.path.isabs(p):
return os.path.abspath(p)
return os.path.abspath(os.path.join(PROJECT_ROOT, p))
def print_help(self):
print("\n指令帮助:")
print(" i 选择并导入文档(绝对路径手动;相对路径默认 /home/sunrise/AI_online_voice/assets/text.docx)")
print(" r [秒数] 录音并提交文档分析(默认 5 秒)")
print(" p 回放最近一次录音")
print(" h 查看帮助")
print(" q 退出\n")
def handle_doc_select(self):
print("[文档选择] 录音 5 秒选择路径类型(说:绝对路径 或 相对路径;相对默认 /home/sunrise/AI_online_voice/assets/text.docx)")
audio_file = self.processor.record(5)
if not audio_file:
print("[错误] 路径类型录音失败")
return
wav_path = self.processor.convert_to_wav(audio_file) or audio_file
selection_text = None
try:
selection_text = self.asr.transcribe_audio_ws(wav_path)
except Exception as e:
print(f"[识别异常] {e}")
choice = None
if selection_text:
t = selection_text.lower()
if ("绝对" in t) or ("absolute" in t):
choice = "abs"
elif ("相对" in t) or ("relative" in t):
choice = "rel"
if not choice:
print("[提示] 未识别到路径类型。请输入:abs(绝对) 或 rel(相对)")
try:
choice = input("路径类型(abs/rel): ").strip().lower()
except Exception:
return
is_abs = choice.startswith("a")
if is_abs:
path_input = input("请输入文档绝对路径: ").strip()
final_path = self._resolve_path(path_input, is_absolute=True)
else:
rel_default_linux = "/home/sunrise/AI_online_voice/assets/text.docx"
rel_default_local = "assets/text.docx"
use_path = rel_default_linux if os.path.exists(rel_default_linux) else rel_default_local
print(f"[使用默认相对路径] {use_path}")
final_path = self._resolve_path(use_path, is_absolute=False)
if not final_path or not os.path.exists(final_path):
print(f"[错误] 文档文件不存在: {final_path}")
print("[示例] 绝对: /home/user/doc.docx | 相对: assets/text.docx")
return
ext = os.path.splitext(final_path)[1].lower()
if ext not in (".docx", ".xlsx"):
print("[错误] 仅支持 .docx 与 .xlsx")
return
self.doc_path = final_path
print(f"[文档已设置] {final_path}")
def handle_record(self, duration_sec: int):
print(f"[操作] 开始录音 {duration_sec} 秒…")
audio_file = self.processor.record(duration_sec)
if not audio_file:
print("[错误] 录音失败")
return
self.last_audio = audio_file
try:
with wave.open(audio_file, "rb") as wf:
print(f"[音频信息] rate={wf.getframerate()}, ch={wf.getnchannels()}, bits={wf.getsampwidth()*8}")
except Exception:
pass
wav_path = self.processor.convert_to_wav(audio_file)
if not wav_path:
print("[错误] 转换 WAV 失败")
return
self.last_wav = wav_path
print("[识别] 讯飞实时识别…")
text = self.asr.transcribe_audio_ws(wav_path)
if not text:
print("[识别失败] 未获取到文本")
return
print(f"[识别结果] {text}")
# 加载文档内容
doc_text = None
if self.doc_path:
doc_text = self.loader.load_text(self.doc_path)
if not doc_text:
print("[文档] 解析失败或为空,按纯文本对话处理")
else:
print("[文档] 未设置文档,将按纯文本对话处理")
print("[豆包] 提交文档分析…")
try:
sys_prompt = getattr(ROOT_CONFIG, "SYSTEM_PROMPT", None) if ROOT_CONFIG else None
messages = []
if sys_prompt:
messages.append({"role": "system", "content": sys_prompt})
# 构造用户消息:识别文本 + 文档内容
if doc_text:
combined = (
"用户问题/指令:\n" + text + "\n\n" + "文档内容片段:\n" + doc_text
)
else:
combined = text
messages.append({"role": "user", "content": combined})
result = self.doubao._make_request(messages)
if result and result.get("choices"):
print("[豆包回复]", result["choices"][0]["message"]["content"])
else:
print("[豆包回复] None")
except Exception as e:
print("[豆包错误]", e)
def handle_play(self):
if not self.last_audio:
print("[提示] 尚无可回放的录音。请先使用 r 指令录音。")
return
print("[播放] 回放最近一次录音…")
self.processor.play(self.last_audio)
def run(self):
print("\n=== 05 文档分析(语音选择文档 + 讯飞 + 豆包)实验 ===")
self.print_help()
try:
first = input("是否先选择文档? (y/n): ").strip().lower()
if first.startswith("y"):
self.handle_doc_select()
except Exception:
pass
while True:
try:
cmd = input("请输入指令 (i/r/p/h/q): ").strip()
except (EOFError, KeyboardInterrupt):
print("\n[退出]")
break
if not cmd:
continue
if cmd == "q":
print("[退出]")
break
if cmd == "h":
self.print_help()
continue
if cmd == "p":
self.handle_play()
continue
if cmd == "i":
self.handle_doc_select()
continue
if cmd.startswith("r"):
parts = cmd.split()
duration = 5
if len(parts) >= 2:
try:
duration = int(parts[1])
except Exception:
print("[提示] 秒数无效,使用默认 5 秒")
self.handle_record(duration)
continue
print("[提示] 未知指令。输入 h 查看帮助。")
if __name__ == "__main__":
VoiceDocumentAnalysisApp().run()