AI在线开发
实验06-摄像头运用-AI视觉分析
实验准备:
- 确保系统已安装python3以及opencv数据库
- 准备一个usb摄像头
实验步骤:
- 将摄像头接入主板,运行
ls /dev/video*,检查摄像头是否接入,程序中使用默认摄像头接口video0,如接口不符可自行更改。 cd AI_online#进入功能包python examples/06_camera_input_loop.py#运行示例程序
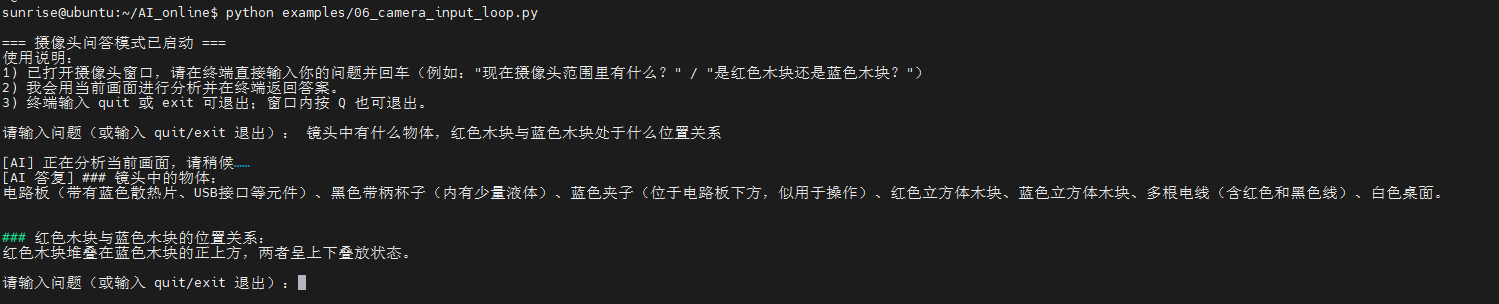
运行终端如下:
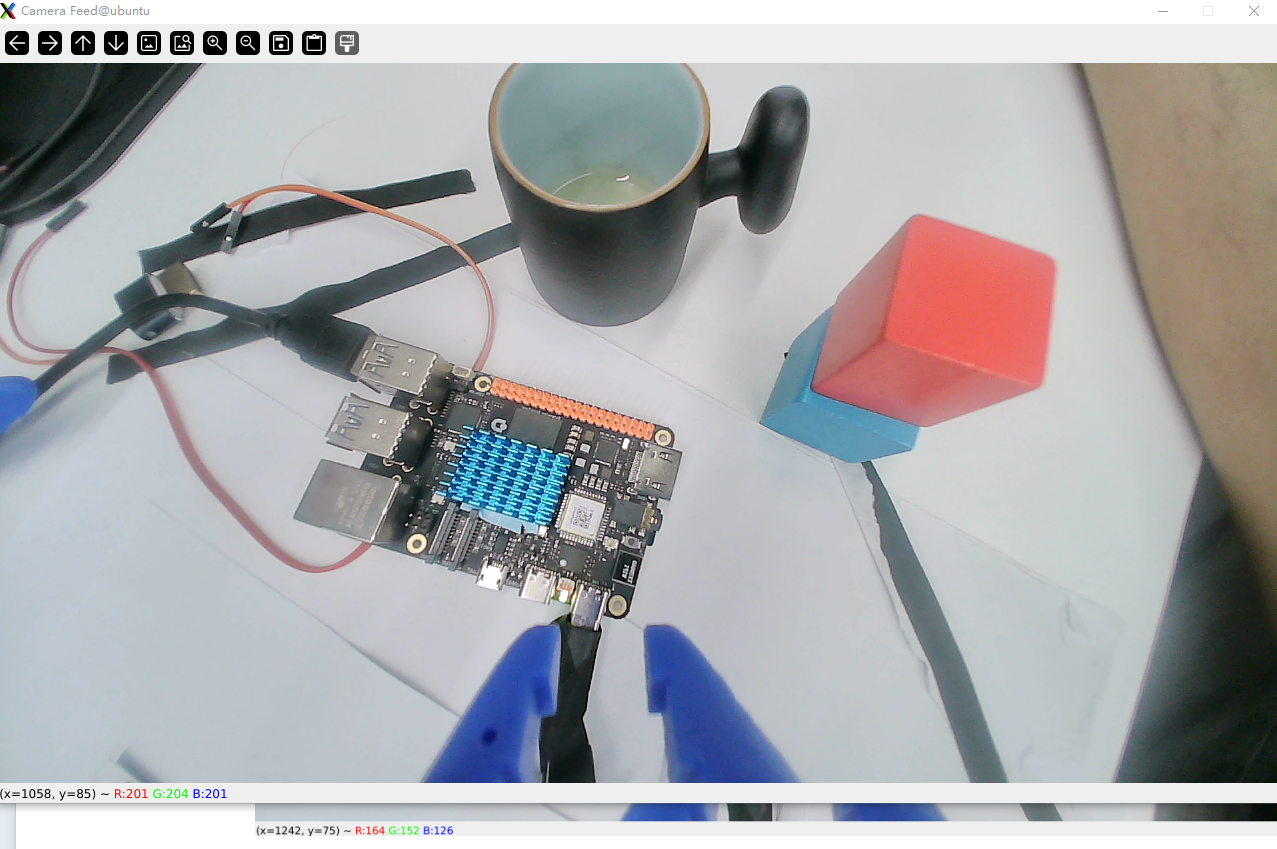
摄像头画面示例:
"""
06_camera_input_loop.py
功能:
- 打开摄像头窗口实时显示画面
- 在终端输入问题后,将“当前帧”发送到 AI 做图文分析并返回回答
- 适用于识别当前画面中有什么、颜色判断(如红色或蓝色木块)等
依赖:
- OpenCV: pip install opencv-python
- 已配置好的 DoubaoAPIClient:请在 utils/config.py 中填写 API_KEY / MODEL_ENDPOINT / API_BASE_URL
"""
import sys
import os
import threading
import time
from typing import Optional
# 尝试导入 OpenCV
try:
import cv2
except ImportError:
print("未安装 OpenCV,请先执行: pip install opencv-python")
sys.exit(1)
# 加入父目录,便于示例脚本直接运行
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from utils.api_client import DoubaoAPIClient
def encode_frame_to_jpeg_bytes(frame) -> Optional[bytes]:
"""将当前帧编码为 JPEG 字节,失败返回 None"""
try:
# 轻度缩放,降低带宽与延迟(保持 16:9/4:3 等比例)
max_w = 960
h, w = frame.shape[:2]
if w > max_w:
scale = max_w / float(w)
new_size = (int(w * scale), int(h * scale))
frame = cv2.resize(frame, new_size, interpolation=cv2.INTER_AREA)
ok, buf = cv2.imencode('.jpg', frame, [int(cv2.IMWRITE_JPEG_QUALITY), 85])
if not ok:
return None
return buf.tobytes()
except Exception as e:
print(f"帧编码失败: {e}")
return None
class CameraQALoop:
"""摄像头输入循环 + 终端问答,将当前画面发送到 AI 进行分析"""
def __init__(self, camera_index: int = 0, window_name: str = "Camera Feed"):
self.camera_index = camera_index
self.window_name = window_name
self.cap: Optional[cv2.VideoCapture] = None
self.running = False
self.latest_frame = None
self.lock = threading.Lock()
self.client: Optional[DoubaoAPIClient] = None
self.input_thread: Optional[threading.Thread] = None
def _init_camera(self) -> bool:
self.cap = cv2.VideoCapture(self.camera_index)
if not self.cap.isOpened():
print(f"无法打开摄像头(index={self.camera_index}),请检查设备或更换索引")
return False
# 可选:设置分辨率,视设备而定
self.cap.set(cv2.CAP_PROP_FRAME_WIDTH, 1280)
self.cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 720)
return True
def _init_client(self) -> bool:
try:
self.client = DoubaoAPIClient()
return True
except Exception as e:
print(f"API 客户端初始化失败:{e}\n请检查 utils/config.py 中的 API_KEY / MODEL_ENDPOINT / API_BASE_URL 配置是否正确")
return False
def _print_intro(self):
print("\n=== 摄像头问答模式已启动 ===")
print("使用说明:")
print("1) 已打开摄像头窗口,请在终端直接输入你的问题并回车(例如:\"现在摄像头范围里有什么?\" / \"是红色木块还是蓝色木块?\")")
print("2) 我会用当前画面进行分析并在终端返回答案。")
print("3) 终端输入 quit 或 exit 可退出;窗口内按 Q 也可退出。\n")
def _answer_with_current_frame(self, question: str):
# 读取最新帧
with self.lock:
frame = None if self.latest_frame is None else self.latest_frame.copy()
if frame is None:
print("暂时没有可用画面,请稍后再试……")
return
image_bytes = encode_frame_to_jpeg_bytes(frame)
if image_bytes is None:
print("当前帧编码失败,未能发送给 AI")
return
# 系统提示词:引导模型专注当前图像进行客观识别与颜色判断
system_prompt = (
"你是一位视觉助手。请始终基于用户提供的当前图像来回答问题,"
"需要进行:物体识别、颜色判断、场景/位置描述、简单关系判断。"
"当图像中信息不足或不确定时,请明确说明不确定并简要给出可能性。"
)
try:
print("\n[AI] 正在分析当前画面,请稍候……")
answer = self.client.chat_with_image(
text=question,
image_data=image_bytes,
image_format="bytes", # 直接发送内存字节
system_prompt=system_prompt,
max_tokens=800,
temperature=0.3
)
if answer:
print(f"[AI 答复] {answer}\n")
else:
print("[AI] 未返回有效答案,请重试或检查网络/API 配置\n")
except Exception as e:
print(f"[AI] 分析失败:{e}\n")
def _input_loop(self):
"""终端输入线程:阻塞读取用户问题,触发当前帧分析"""
while self.running:
try:
question = input("请输入问题(或输入 quit/exit 退出):").strip()
except EOFError:
# 终端被关闭或无输入源
question = "quit"
if question.lower() in ("quit", "exit"):
self.running = False
break
if not question:
continue
self._answer_with_current_frame(question)
def start(self):
if not self._init_camera():
return
if not self._init_client():
# 即使 AI 客户端失败,也允许预览摄像头;但无法问答
print("提示:你仍可查看摄像头窗口,但无法进行 AI 问答。")
self.running = True
self._print_intro()
# 启动输入线程
self.input_thread = threading.Thread(target=self._input_loop, daemon=True)
self.input_thread.start()
# 摄像头显示主循环
try:
while self.running:
ret, frame = self.cap.read()
if not ret:
print("读取摄像头帧失败,尝试继续……")
time.sleep(0.05)
continue
# 更新当前帧
with self.lock:
self.latest_frame = frame
# 在窗口显示
cv2.imshow(self.window_name, frame)
key = cv2.waitKey(1) & 0xFF
if key in (ord('q'), ord('Q')):
self.running = False
break
print("正在退出……")
finally:
self.stop()
def stop(self):
try:
if self.cap:
self.cap.release()
cv2.destroyAllWindows()
except Exception:
pass
self.running = False
# 等待输入线程结束
if self.input_thread and self.input_thread.is_alive():
try:
self.input_thread.join(timeout=1.0)
except Exception:
pass
print("已关闭摄像头与窗口。")
def main():
import argparse
parser = argparse.ArgumentParser(description="摄像头输入循环 + AI 图文问答")
parser.add_argument("--index", type=int, default=0, help="摄像头索引(默认0)")
args = parser.parse_args()
loop = CameraQALoop(camera_index=args.index)
loop.start()
if __name__ == "__main__":
main()