语音LLM应用
实验02-语音对话
实验准备:(注册登录豆包AI账号,如有直接填入信息即可)
(实验前提:已完成实验01的依赖包下载及讯飞账号注册等操作)
- 获取API Key: https://console.volcengine.com/ark/region:ark+cn-beijing/apiKey
- 获取模型接入点ID: https://console.volcengine.com/ark/region:ark+cn-beijing/endpoint
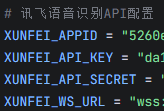
- 在config.py中替换个人API Key和模型接入点,模型接入点以ep-开头
实验步骤:(确保语音模块已连接)
cd AI_online_voice#进入主目录python examples/02_voice_dialogue.py#运行示例程序
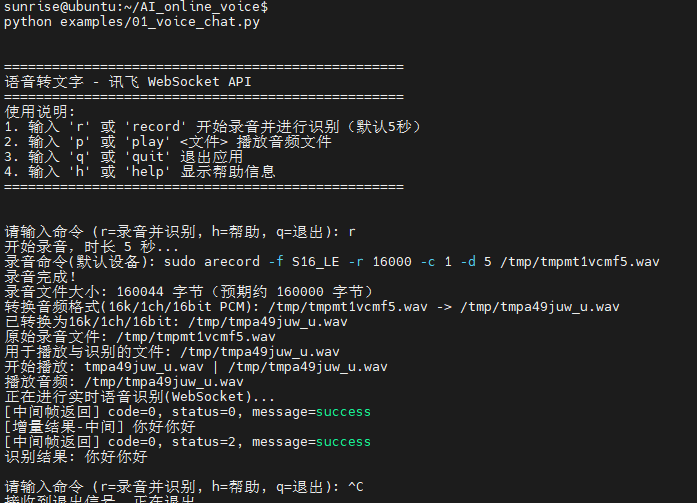
实验结果如下:
# -*- coding: utf-8 -*-
"""
02_voice_dialogue.py
实验说明:
- 在 01_voice_chat.py 的基础上,复用录音、播放与实时讯飞语音识别流程;
- 将识别出的中文文本发送给豆包,并把豆包的回答打印到终端;
- 不修改其他文件,仅新增本实验脚本;
- 参考 01_image_analysis.py 的豆包返回方式,调用 DoubaoAPIClient.chat_text。
使用方法:
- python examples/02_voice_dialogue.py
- 交互命令:
- r [秒数]:录音指定秒数,识别,并将结果发给豆包,打印豆包回复
- p:回放最近一次录音(如果存在)
- q:退出
- h:帮助
"""
import os
import sys
import json
import time
import base64
import hmac
import ssl
import hashlib
import wave #语音音频处理重要文件
from email.utils import formatdate
from urllib.parse import quote, urlparse
# 允许作为独立脚本运行时导入上级目录
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
PROJECT_ROOT = os.path.dirname(CURRENT_DIR)
sys.path.append(PROJECT_ROOT)
# 加载根目录 config.py 以获取豆包API的正确配置
WORKSPACE_ROOT = os.path.dirname(PROJECT_ROOT)
import importlib.util # noqa: E402
ROOT_CONFIG = None
_root_cfg_path = os.path.join(WORKSPACE_ROOT, "config.py")
if os.path.exists(_root_cfg_path):
try:
_spec = importlib.util.spec_from_file_location("root_config", _root_cfg_path)
ROOT_CONFIG = importlib.util.module_from_spec(_spec)
_spec.loader.exec_module(ROOT_CONFIG)
except Exception:
ROOT_CONFIG = None
from utils.audio_processor import AudioProcessor # noqa: E402
import requests # 本地实现豆包客户端,避免导入冲突
import config # noqa: E402
class DoubaoAPIClient:
"""简化版豆包API客户端,内联实现文本聊天以避免导入冲突"""
def __init__(self):
cfg = ROOT_CONFIG if ROOT_CONFIG else config
self.api_key = getattr(cfg, "API_KEY", None)
self.model_endpoint = getattr(cfg, "MODEL_ENDPOINT", None)
self.base_url = getattr(cfg, "API_BASE_URL", None)
self.timeout = getattr(cfg, "REQUEST_TIMEOUT", 30)
if not self.api_key or not self.model_endpoint or not self.base_url:
raise ValueError("请在 config.py 中配置 API_KEY / MODEL_ENDPOINT / API_BASE_URL")
def _make_request(self, messages, **kwargs):
try:
base = (self.base_url or "").rstrip('/')
url = base if base.endswith('chat/completions') else f"{base}/chat/completions"
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json",
"Accept": "application/json",
}
data = {
"model": self.model_endpoint,
"messages": messages,
"temperature": kwargs.get("temperature", 0.7),
"max_tokens": kwargs.get("max_tokens", 1000),
"top_p": kwargs.get("top_p", 0.9),
"stream": kwargs.get("stream", False),
}
for k, v in kwargs.items():
if k not in data:
data[k] = v
resp = requests.post(url, json=data, headers=headers, timeout=self.timeout)
if resp.status_code == 200:
try:
return resp.json()
except Exception as e:
print(f"[豆包] JSON解析失败: {e}")
print(f"[豆包] 响应文本片段: {resp.text[:500]}")
return None
else:
print(f"[豆包] API请求失败: {resp.status_code}")
print(f"[豆包] 请求URL: {url}")
print(f"[豆包] 模型: {self.model_endpoint}")
try:
err_json = resp.json()
print(f"[豆包] 错误详情(JSON): {json.dumps(err_json, ensure_ascii=False)[:500]}")
except Exception:
print(f"[豆包] 错误详情(Text): {resp.text[:500]}")
if resp.status_code == 401:
print("[豆包] 认证失败,请检查 API_KEY")
elif resp.status_code == 404:
print("[豆包] 接入点不存在,请检查 MODEL_ENDPOINT")
elif resp.status_code == 429:
print("[豆包] 请求频率过高,请稍后重试")
elif resp.status_code == 500:
print("[豆包] 服务器内部错误,请稍后重试")
return None
except Exception as e:
print(f"豆包请求异常: {e}")
return None
def chat_text(self, text: str, system_prompt: str = None, **kwargs):
try:
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": text})
result = self._make_request(messages, **kwargs)
if result and "choices" in result and result["choices"]:
return result["choices"][0]["message"]["content"]
return None
except Exception as e:
print(f"文本对话失败: {e}")
return None
try:
import websocket
from websocket import WebSocketTimeoutException
except Exception: # pragma: no cover
websocket = None
WebSocketTimeoutException = Exception
class XunfeiRealtimeSpeechClient:
"""简化版的讯飞实时语音识别客户端(WebSocket)。
- 复用我们在 01_voice_chat.py 中优化过的健壮性:
- 安全 JSON 解析
- 增量文本聚合
- 超时容错,返回已识别的文本
"""
def __init__(self):
self.app_id = getattr(config, "XUNFEI_APPID", "")
self.api_key = getattr(config, "XUNFEI_API_KEY", "")
self.api_secret = getattr(config, "XUNFEI_API_SECRET", "")
self.host_url = getattr(config, "XUNFEI_WS_URL", "")
self.timeout = getattr(config, "REQUEST_TIMEOUT", 15)
def _safe_json_loads(self, s):
try:
return json.loads(s)
except Exception:
return None
def _build_auth_url(self):
url = self.host_url
# 使用标准库解析,兼容不同 websocket-client 版本
try:
parsed = urlparse(url)
host = parsed.netloc or url.split("//")[-1].split("/")[0]
path = parsed.path or "/v2/iat"
except Exception:
host = url.split("//")[-1].split("/")[0]
path = "/v2/iat"
# 鉴权:生成签名字符串
date = formatdate(timeval=None, localtime=False, usegmt=True)
signature_origin = f"host: {host}\ndate: {date}\nGET {path} HTTP/1.1"
signature_sha = hmac.new(
self.api_secret.encode("utf-8"),
signature_origin.encode("utf-8"),
digestmod=hashlib.sha256,
).digest()
signature = base64.b64encode(signature_sha).decode("utf-8")
authorization_origin = (
f"api_key=\"{self.api_key}\", algorithm=\"hmac-sha256\", headers=\"host date request-line\", signature=\"{signature}\""
)
authorization = base64.b64encode(authorization_origin.encode("utf-8")).decode("utf-8")
auth_url = f"{url}?authorization={quote(authorization)}&date={quote(date)}&host={quote(host)}"
return auth_url
def transcribe_audio_ws(self, wav_path):
if websocket is None:
print("[错误] 缺少 websocket-client 依赖,请安装后重试:pip install websocket-client")
return None
# 读取音频数据
try:
with open(wav_path, "rb") as f:
audio_bytes = f.read()
except Exception as e:
print(f"[错误] 读取音频失败: {e}")
return None
# 初始化增量聚合
final_text_parts = []
saw_final_status = False
url = self._build_auth_url()
print(f"[WS] 连接: {url}")
ws = websocket.create_connection(url, timeout=self.timeout, sslopt={"cert_reqs": ssl.CERT_NONE})
try:
# 发送首帧
init_payload = {
"common": {"app_id": self.app_id},
"business": {
"language": "zh_cn",
"domain": "iat",
"accent": "mandarin",
"vad_eos": 2000,
},
"data": {
"status": 0,
"format": "audio/L16;rate=16000",
"audio": base64.b64encode(audio_bytes[:1200]).decode("utf-8"),
"encoding": "raw",
},
}
ws.send(json.dumps(init_payload))
print("[首帧发送] bytes=", len(audio_bytes[:1200]))
# 发送中间帧(简单一次性发送余下数据)
middle_payload = {
"data": {
"status": 1,
"format": "audio/L16;rate=16000",
"audio": base64.b64encode(audio_bytes[1200:]).decode("utf-8"),
"encoding": "raw",
}
}
ws.send(json.dumps(middle_payload))
print("[中间帧发送] bytes=", len(audio_bytes[1200:]))
# 发送结束帧
end_payload = {
"data": {"status": 2, "format": "audio/L16;rate=16000", "audio": "", "encoding": "raw"}
}
ws.send(json.dumps(end_payload))
print("[结束帧发送]")
# 接收返回,聚合文本
while True:
try:
msg = ws.recv()
except WebSocketTimeoutException:
print("[WS] 接收超时,返回已聚合文本")
break
except Exception as e:
print(f"[WS] 接收异常: {e}")
break
data = self._safe_json_loads(msg)
if not data:
print("[WS] 非法 JSON,忽略")
continue
code = data.get("code", -1)
status = data.get("data", {}).get("status")
message = data.get("message")
print(f"[WS返回] code={code}, status={status}, message={message}")
if code != 0:
print("[WS] 识别失败: ", data)
break
# 解析增量识别文本
result = data.get("data", {}).get("result")
if result and result.get("ws"):
# 将分段结果拼接
parts = []
for ws_seg in result.get("ws", []):
for cw in ws_seg.get("cw", []):
w = cw.get("w")
if w:
parts.append(w)
if parts:
final_text_parts.append("".join(parts))
print("[增量结果] ", "".join(parts))
if status == 2:
saw_final_status = True
print("[WS] 收到最终状态,结束接收")
break
finally:
try:
ws.close()
except Exception:
pass
aggregated = "".join(final_text_parts).strip()
if aggregated:
return aggregated
if saw_final_status:
return aggregated # 为空也返回
return None
class VoiceDialogueApp:
def __init__(self):
self.processor = AudioProcessor()
self.asr_client = XunfeiRealtimeSpeechClient()
self.doubao = DoubaoAPIClient()
self.last_audio = None
self.last_wav = None
def print_help(self):
print("\n指令帮助:")
print(" r [秒数] 录音指定秒数,识别,并发给豆包")
print(" p 回放最近一次录音")
print(" h 查看帮助")
print(" q 退出\n")
def handle_record(self, duration_sec: int):
print(f"[操作] 开始录音 {duration_sec} 秒…")
audio_file = self.processor.record(duration_sec)
if not audio_file:
print("[错误] 录音失败")
return
self.last_audio = audio_file
print(f"[录音完成] 文件: {audio_file}")
try:
with wave.open(audio_file, "rb") as wf:
print(f"[原始音频信息] rate={wf.getframerate()}, ch={wf.getnchannels()}, width={wf.getsampwidth()*8}bit, frames={wf.getnframes()}")
except Exception as e:
print(f"[原始音频信息读取失败] {e}")
wav_path = self.processor.convert_to_wav(audio_file)
if not wav_path:
print("[错误] 转换 WAV 失败")
return
self.last_wav = wav_path
print(f"[转换完成] WAV 文件: {wav_path}")
try:
with wave.open(wav_path, "rb") as wf:
duration = (wf.getnframes() / float(wf.getframerate())) if wf.getframerate() else 0.0
print(f"[转换后音频信息] rate={wf.getframerate()}, ch={wf.getnchannels()}, width={wf.getsampwidth()*8}bit, secs={duration:.2f}")
except Exception as e:
print(f"[转换后音频信息读取失败] {e}")
print("[识别] 发送至讯飞实时识别…")
text = self.asr_client.transcribe_audio_ws(wav_path)
if not text:
print("[识别失败] 未获取到文本")
return
print(f"[识别结果] {text}")
print("[豆包] 发送识别结果到豆包,等待回复…")
try:
sys_prompt = getattr(ROOT_CONFIG, "SYSTEM_PROMPT", None) if ROOT_CONFIG else None
reply = self.doubao.chat_text(text, system_prompt=sys_prompt)
if reply:
print("[豆包回复]", reply)
else:
print("[豆包回复] None")
except Exception as e:
print("[豆包错误] ", e)
def handle_play(self):
if not self.last_audio:
print("[提示] 尚无可回放的录音。请先使用 r 指令录音。")
return
print("[播放] 回放最近一次录音…")
self.processor.play(self.last_audio)
def run(self):
print("\n=== 02 语音对话(讯飞 + 豆包)实验 ===")
print("已接入讯飞语音识别;将识别结果发送给豆包并返回终端。")
self.print_help()
while True:
try:
cmd = input("请输入指令 (r/p/h/q): ").strip()
except (EOFError, KeyboardInterrupt):
print("\n[退出]")
break
if not cmd:
continue
if cmd == "q":
print("[退出]")
break
if cmd == "h":
self.print_help()
continue
if cmd == "p":
self.handle_play()
continue
if cmd.startswith("r"):
parts = cmd.split()
duration = 5
if len(parts) >= 2:
try:
duration = int(parts[1])
except Exception:
print("[提示] 秒数无效,使用默认 5 秒")
self.handle_record(duration)
continue
print("[提示] 未知指令。输入 h 查看帮助。")
if __name__ == "__main__":
VoiceDialogueApp().run()