ClawChips 架构与原理
ClawChips 是 Rockchip(瑞芯微)开源的边缘 AI Agent 部署方案,基于 OpenClaw 框架,专为 RK3588 + RK1828 平台优化。视美泰AI龙虾平台对 ClawChips 进行了深度适配和优化。
整体架构
QQ / Channel 消息
│
▼
┌──────────────────┐
│ OpenClaw │
│ Agent Gateway │
└────────┬─────────┘
│
▼
┌──────────────────┐ ┌─────────────────┐
│ ClawChips │────▶│ 云端模型 │
│ Local Router │ │ (DeepSeek等) │
└────────┬─────────┘ └─────────────────┘
│
▼
┌──────────────────┐ ┌─────────────────┐
│ ModelHub │────▶│ ASR / TTS / │
│ Scheduler │ │ VLM / Embedding│
└──────────────────┘ └────────┬────────┘
│
┌───────┴───────┐
│ RK1828 NPU │
│ (协处理器) │
└───────────────┘ModelHub 模型调度
ModelHub 是 ClawChips 的本地模型服务调度网关,位于应用逻辑和具体模型服务之间。
职责:
- 用 YAML 描述 RK3588、RK1828 等设备的模型服务
- 根据设备并发和内存情况调度任务,避免多个重模型争抢资源
- 自动执行模型服务的启动、停止、健康检查
- 转发 HTTP 请求到目标模型服务(兼容 OpenAI 风格 API)
调用链:
SKILL (rk-asr/rk-tts/rk-vl)
│
▼
ModelHub
(调度/API)
│
┌───┼───┬───────┐
▼ ▼ ▼ ▼
ASR TTS VLM Embedding上层 SKILL 不需要关心模型是否启动、设备是否忙碌、端口如何分配,只需通过统一 API 提交任务。
配置文件位于 ~/.openclaw/clawchips.yaml,详细安装和客户端调用示例请参考 ModelHub 文档。
端云智能路由
端云智能路由是 ClawChips 插件的核心功能,位于 OpenClaw 和模型后端之间,自动识别任务复杂度并在本地和云端模型间智能调度。
┌──────────┐ ┌─────────────┐ ┌──────────────┐
│ QQ / │────▶│ OpenClaw │─────────────▶│ 云端模型 │
│ Channel │ │ Gateway │ ┌───────│ DeepSeek │
└──────────┘ └──────┬──────┘ │ │ Qwen / GPT │
│ │ └──────────────┘
▼ │
┌──────────────┐ │ ┌──────────────┐
│ ClawChips │ └──────▶│ 本地模型 │
│ LocalRouter │ │ rkllm3-server│
└──────────────┘ └──────────────┘
│
▼
┌──────────────┐
│ RK SKILL │
│ (ASR/TTS/VLM)│
└──────────────┘路由策略在 ~/.openclaw/clawchips.yaml 中配置:
router:
strategy: rules # 路由策略:rules(规则)或 memory(记忆)
rules:
- LOCAL: rkllm/Qwen3-1.7B # 本地模型路由
- CLOUD: deepseek/deepseek-chat # 云端模型路由
- default: deepseek/deepseek-chat # 默认路由
enable: true| 模式 | 说明 |
|---|---|
rules | 基于规则路由,按 LOCAL/CLOUD/default 标签匹配 |
memory | 基于记忆路由,根据历史决策持续优化路由准确性 |
配置云端模型
编辑 ~/.openclaw/openclaw.json,在 models.providers 中添加云端 Provider:
{
"models": {
"providers": {
"deepseek": {
"baseUrl": "https://api.deepseek.com/v1",
"api": "openai-completions",
"apiKey": "sk-xxxxxxxxxxxx",
"models": [
{
"id": "deepseek-chat",
"name": "DeepSeek V3",
"reasoning": false,
"input": ["text"],
"contextWindow": 65536,
"maxTokens": 4096
}
]
}
}
}
}同步更新 Agent 级配置 ~/.openclaw/agents/main/agent/models.json,添加相同的 provider。
Dashboard 配置
访问 http://<开发板IP>:18789/plugins/clawchips/dashboard:
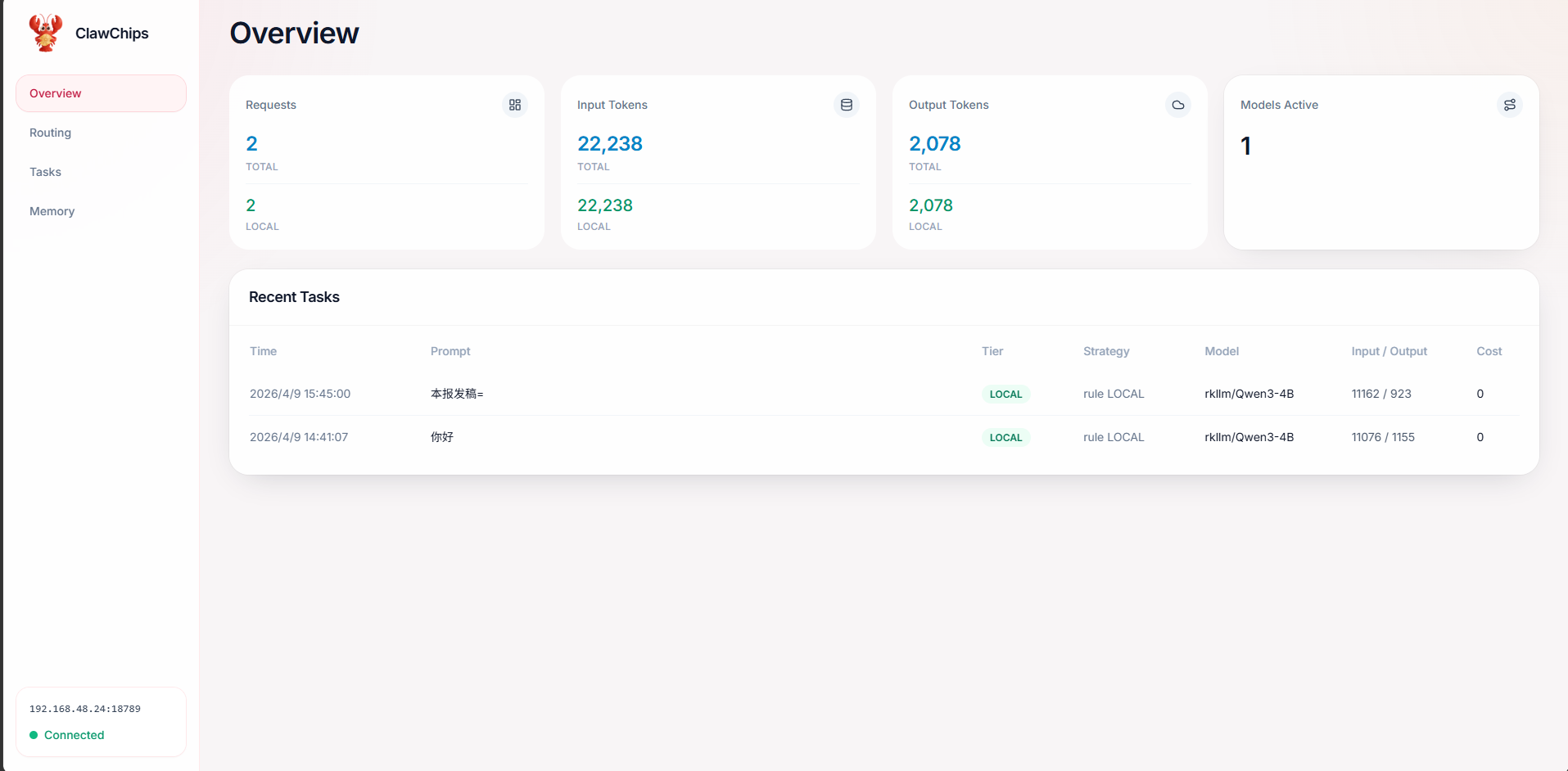
- 使能本地路由和记忆路由
- 选择 CLOUD model ID(下拉选择已配置的云端模型)
- 保存配置后重启:
openclaw gateway restart
视美泰实践:端云协同
推荐方案:云端 DeepSeek 负责对话推理,本地 NPU 负责 VLM 图片识别,两者同时工作互不干扰。
Token 消耗优化
视美泰最佳实践:OpenClaw 每轮对话消耗的 API token 直接影响成本。
| 策略 | 每轮 token | 说明 |
|---|---|---|
| 默认(先读 SKILL.md 再执行) | ~68K / 4轮 | AI 先 cat SKILL 了解用法 |
| TOOLS.md 内联(跳过读 SKILL.md) | ~33K / 2轮 | 工具用法直接写在 TOOLS.md |
| 节省 | 51% | 功能零损失 |
将常用工具的调用方式直接写在 ~/.openclaw/workspace/TOOLS.md 中,AI 不需要先读取 SKILL.md 就能直接调用工具,省去一整轮 API 调用。
常见问题
ClawChips 路由始终覆盖到本地模型
现象:日志显示 [hooks] provider overridden to rkllm,即使 default 配置为云端模型。
解决:将 LOCAL 规则也指向云端模型(当不需要本地模型时):
router:
rules:
- LOCAL: deepseek/deepseek-chat
- CLOUD: deepseek/deepseek-chat
- default: deepseek/deepseek-chat本地模型响应超时
原因:OpenClaw 的系统提示词即使使用 minimal 工具配置也有 ~7000 tokens,本地 RK3588 处理速度约 130 tok/s,需要约 54 秒,超过超时限制。
解决:使用云端模型处理对话(推荐),或增大超时时间。
NPU 设备找不到
解决:
- 检查 RK1828 模组是否插紧
- 检查
rknn3.service状态:sudo systemctl status rknn3.service - 检查 PCIe 设备:
lspci | grep -i "182\|accel" - 必要时重启开发板