SKILL 使用手册
ClawChips 内置了一系列基于 RK1828 模组运行的算法 SKILL,可通过 QQ 机器人直接对话触发。
使用前提
- 算法模型已安装:ASR/TTS/VLM 模型权重随 ClawChips 固件预装,位于
/userdata/下 - RK1828 NPU 正常:
rknn3_transfer_proxy devices能检测到设备 - ModelHub 运行中:负责调度底层模型服务
- 未运行本地大模型:本地 LLM 会占满 RK1828 内存,导致 SKILL 不可用
重要
本地大模型和 SKILL 算法互斥。启动本地大模型后,RK1828 内存基本占满,无法同时使用 ASR/TTS/VLM/RAG。推荐使用云端模型对话 + 本地 NPU 跑 SKILL。
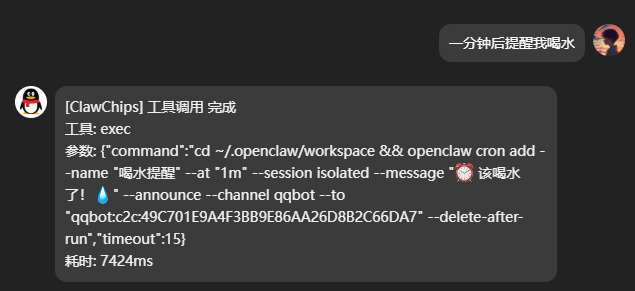
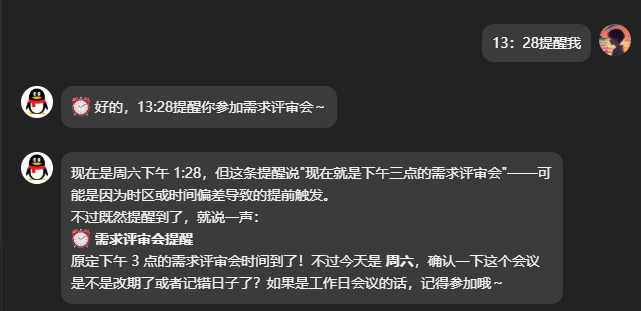
rk-remind 定时提醒
通过 QQ 机器人对话创建、查询、取消提醒,支持一次性和周期性任务。

| 用户说法 | Agent 行为 |
|---|---|
| "5分钟后提醒我喝水" | 计算绝对时间 → 创建一次性提醒 |
| "每天8点提醒我打卡" | 创建 cron 周期任务 0 8 * * * |
| "工作日9点提醒开会" | 创建 cron 任务 0 9 * * 1-5 |
| "我有哪些提醒" | 查询列表 openclaw cron list |
| "取消喝水提醒" | 查询后删除 openclaw cron remove <id> |
morning-briefing 早安播报
视美泰自研 Skill。每天早上自动推送一条消息,包含:问候 + 天气 + 今日提醒。(图中示例因时间关系选择下午进行展示)
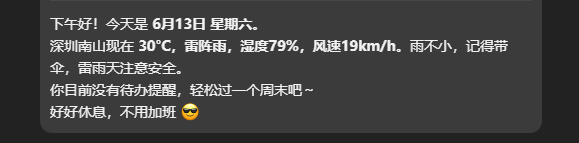
早上好!今天是 6月13日 星期五。
深圳今天 31°C 多云,紫外线强,记得防晒。
你今天有 2 个安排:
- 14:00 需求评审会
- 18:30 买猫粮
加油,打工人!在 QQ 中对机器人说 "每天早上8点给我发早安播报" 即可开启。自定义:
| 需求 | 操作 |
|---|---|
| 改时间 | "把早安播报改到7点半" |
| 改周期 | "工作日才播报" |
| 取消 | "取消早安播报" |
rk-vl 图片识别
基于 Qwen3-VL-2B 的视觉语言模型,支持 USB 摄像头监控和 QQ 发图识别两种场景。
USB 摄像头监控
用户:帮我监控摄像头,当有快递出现的时候提醒我
机器人:已开启摄像头监控,目标为「快递」。检测到时会立即提醒你。重要
使用摄像头监控需要外接 USB 摄像头。
QQ 发图识别

手机拍照发送给 QQ 机器人即可获取相关信息,AI 自动识别并描述内容。
工作原理:
用户在 QQ 发图 → OpenClaw 接收图片 → AI 调用 vl.sh → VLM 服务推理 → 返回描述VLM 推理服务以 systemd 常驻方式运行,视美泰封装的 VLM 推理服务端口 127.0.0.1:7879:
# 检查服务状态
systemctl status vlm.service
# 调用测试
bash /userdata/models/Qwen3-VL-2B/vl.sh "/path/to/image.jpg" "<image>描述这张图片"
# 返回 JSON: {"text": "图片描述...", "vision_ms": 130, "llm_ms": 500}基于 rknn3-toolkit-lite Python API,支持图片路径输入、Base64 输入、自定义 prompt、线程安全多请求并发。
VLM 性能数据
| 阶段 | 耗时 | 说明 |
|---|---|---|
| Vision 推理 | ~130ms | 图片编码到 embedding |
| LLM 推理 | 300-700ms | 根据 prompt 复杂度 |
| 端到端 | <1s | 从收到图到返回描述 |
| 组件 | NPU 内存占用 |
|---|---|
| VLM 常驻服务 | ~2GB / 5GB |
| 云端 API 对话 | 0 |
| 可用剩余 | ~3GB |
关键:VLM 常驻 + 云端 API 对话可以同时工作,VLM 只占 NPU 内存,对话走网络不占 NPU。
rk-asr 语音识别
将音频文件转换为文字,支持板端音频路径和 QQ 直接上传。
用户:帮我转录音频文件:/userdata/40s_rkdc.wav
机器人:(返回转录文字,长音频生成 TXT 文档)短音频(30 秒内)直接返回文字,长音频(超过 30 秒)生成 TXT 文档。在 QQ 聊天框直接发送音频文件也可触发。
rk-tts 语音合成
文字转语音,支持返回音频文件或开发板直接播放。
用户:帮我把下面这段话转成音频:"夜幕笼罩着古老的城堡..."
机器人:(发送音频文件)rk-rag 知识库问答
将 Markdown 文档分块、向量化并存储到本地 SQLite 数据库,基于语义相似度检索相关内容,结合云端大模型生成回答。
用户:帮我将 RK1828-FAQ.md 加入 rk 知识库
机器人:目标知识库:rk1828.db / 新增 chunk:16 条 / chunk 总数:16 条
用户:根据 rk1828 知识库,RK1828 的推理速度是多少
机器人:(基于知识库内容生成回答)部署 Embedding Server
RAG 检索依赖 Embedding Server(bge-small-zh-v1.5 模型,512 维),纯 numpy 推理,CPU 上运行,不占用 NPU。
# 下载模型
pip3 install modelscope
modelscope download --model BAAI/bge-small-zh-v1.5 --local-dir ~/embedding-server/models/bge-small-zh
# 安装依赖
python3 -m venv ~/embedding-server
source ~/embedding-server/bin/activate
pip install fastapi uvicorn numpy safetokens
# 启动
~/embedding-server/bin/python3 ~/embedding-server/server.py
# 默认监听 http://0.0.0.0:18080
# 验证
curl -s http://localhost:18080/v1/embeddings \
-H "Content-Type: application/json" \
-d '{"model":"bge-small-zh-v1.5","input":"测试文本"}' \
| python3 -c "import sys,json; d=json.load(sys.stdin); print('维度:', len(d['data'][0]['embedding']))"
# 输出: 维度: 512rk-meeting-watcher 会议监控
实时监听会议语音,匹配预设关键词,命中后推送 QQ 提醒。
重要
需提前安装 alsa-utils:sudo apt install alsa-utils。建议搭配外接 USB 麦克风。
用户:开启会议监听,关键词"龙虾"
机器人:已开启会议监听。
(命中关键词后推送)
机器人:您设置的关键词已触发,请关注会议!rk-binary-image-decoder 二进制图片解码
将摄像头/ISP 输出的裸像素数据(.bin/.raw/.yuv)转换为 PNG 图片。支持 NV12/NV16/NV24/AB24/BG24/NV15/NV20 格式。
python3 <技能目录>/scripts/CVT_NV12.py camera_capture.bin 1920 1080 1920 output.png| NV12 | NV16 | NV24 |
|---|---|---|
 |  |  |
自定义 Skill 开发
每个 Skill 位于 ~/.openclaw/workspace/skills/<skill-name>/ 目录下:
skills/
└── my-skill/
├── TOOLS.md # Skill 工具定义(OpenClaw 读取)
├── run.py # Skill 主逻辑
├── config.yaml # Skill 配置(可选)
└── requirements.txt # Python 依赖(可选)TOOLS.md 定义 Skill 提供给 Agent 的工具描述:
# My Skill Tools
## my_tool_name
**Description**: 对这个工具的描述,当用户说xxx时调用此工具
**Parameters**:
- `param1` (string, required): 参数1说明
**Returns**: 返回结果的描述开发流程:
- 在
~/.openclaw/workspace/skills/下创建 Skill 目录 - 编写
TOOLS.md定义工具描述 - 编写
run.py实现工具逻辑 - 通过 QQ 机器人对话触发测试
参考链接: