LLM 推理
RK1828 支持多种 LLM 推理方式:C 语言 CLI、HTTP API 服务、Web 聊天界面。
提示
本文中 <模型目录> 为模型存放的根路径,请替换为实际路径(如 /root/AI4x/models、/userdata/models 等)。
C 语言推理测试 (rknn3_llm_demo)
使用 rknn3_llm_demo 进行推理测试(纯 CLI benchmark,非服务):
rknn3_llm_demo \
-m <模型目录>/Qwen3-1.7B/Qwen3-1.7B.rknn \
-w <模型目录>/Qwen3-1.7B/Qwen3-1.7B.weight \
-tk <模型目录>/Qwen3-1.7B/Qwen3-1.7B.tokenizer.gguf \
-em <模型目录>/Qwen3-1.7B/Qwen3-1.7B.embed.bin \
-c 0xff \
-ctx 16384 \
-no 4096 \
-d 0参数说明:
| 参数 | 说明 |
|---|---|
-m | RKNN 模型路径 |
-w | 模型权重路径 |
-tk | 分词器路径 |
-em | Embedding 路径 |
-c | NPU core mask(0xff = 三核全开,3 核并行比单核快约 40%) |
-ctx | 最大上下文长度(不要超过模型 max_context_len) |
-no | 最大生成 token 数 |
-d | 设备 ID(多 NPU 时用,单设备写 0) |
提示
/usr/bin/rknn3_llm_demo 的近似版本(含官方例程)可在 rknn3-model-zoo 仓库获取。Model Zoo 里的 demo 使用位置参数(0xff 作为第 5 个参数),本文给出的 -c 0xff 是对应到 flag 风格的等价写法。完整 flag 以本机 --help 为准。
预期输出:
===== RKNN3_LLM_TEST Results Summary =====
Model: Qwen3-1.7B
DeviceID: 0004:41:00.0
TTFT: 63.130 ms
TPOT: 8.280 ms
Prefill: 316.807 tokens/s
TPS: 120.778 tokens/s
TotalTime: 468.834 ms
TotalRuns: 1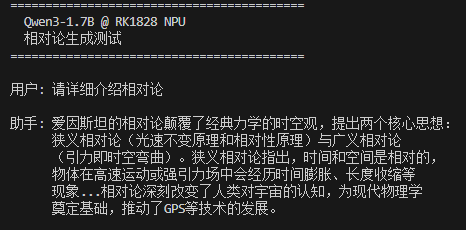
HTTP 推理服务 (rkllm3-server)
rkllm3-server 提供 OpenAI 兼容 API,支持任何使用 OpenAI SDK 的应用直接接入。
rkllm3-server \
-m <模型目录>/Qwen3-1.7B/Qwen3-1.7B.rknn \
--weight <模型目录>/Qwen3-1.7B/Qwen3-1.7B.weight \
--vocab <模型目录>/Qwen3-1.7B/Qwen3-1.7B.tokenizer.gguf \
--embed <模型目录>/Qwen3-1.7B/Qwen3-1.7B.embed.bin \
--host 0.0.0.0 --port 8080 \
-c 2048参数说明:
| 参数 | 说明 |
|---|---|
-m | RKNN 模型路径 |
--weight | 模型权重路径 |
--vocab | 分词器路径 |
--embed | Embedding 路径 |
--host | 监听地址(默认 127.0.0.1) |
--port | 监听端口(默认 8080) |
-c | 上下文长度(受模型 max_context_len 限制) |
API 接口
# 列出模型
curl http://localhost:8080/v1/models
# 对话推理
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model":"qwen","messages":[{"role":"user","content":"你好"}]}'Python SDK 接入
from openai import OpenAI
client = OpenAI(base_url="http://<设备IP>:8080/v1", api_key="none")
response = client.chat.completions.create(
model="qwen",
messages=[
{"role": "system", "content": "你是一个助手"},
{"role": "user", "content": "你好"},
],
max_tokens=100,
)
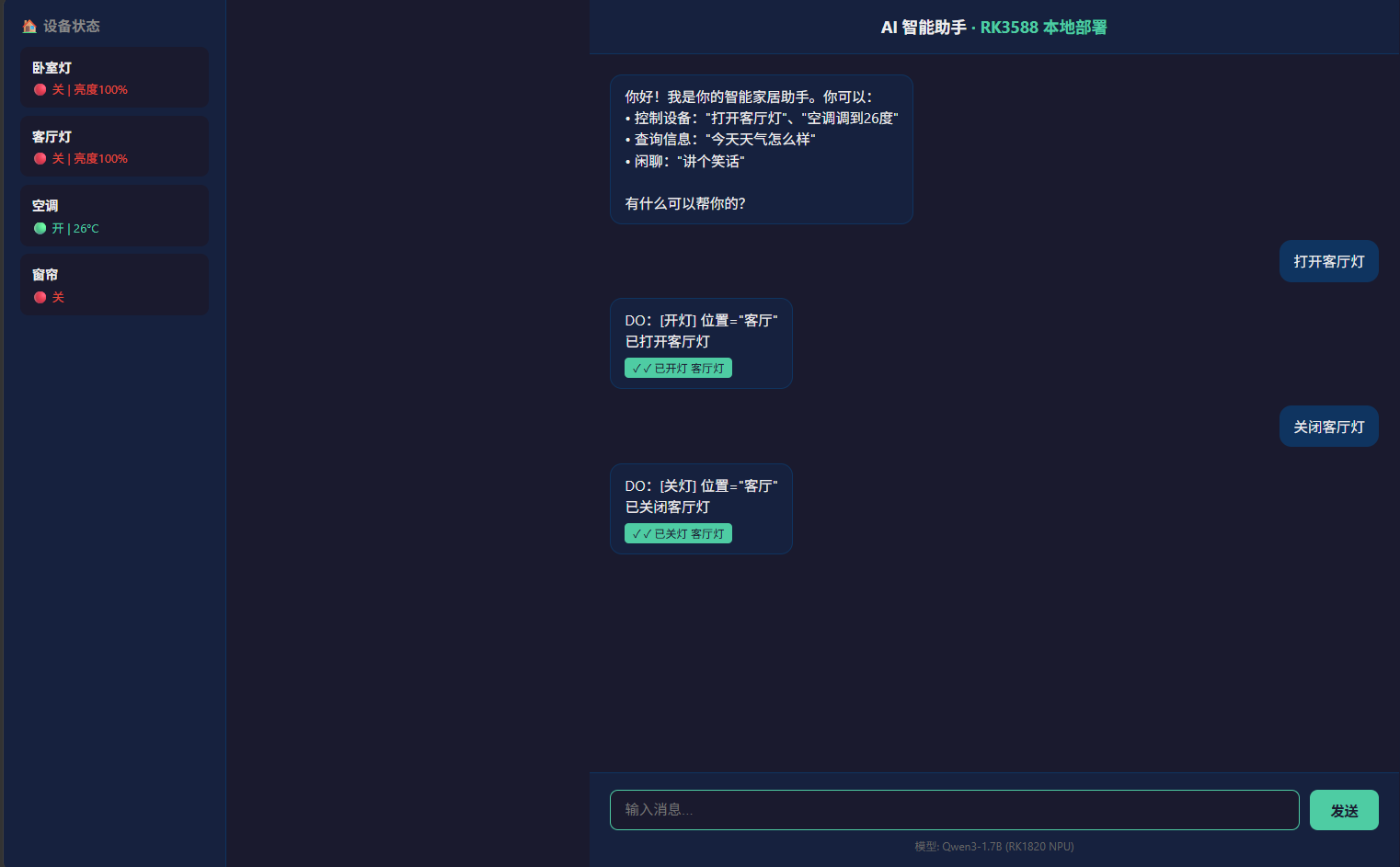
print(response.choices[0].message.content)Web 聊天界面
基于 Flask + 原生前端的轻量 Web 聊天界面,直接对接 rkllm3-server API。支持自然语言对话和模拟设备控制。
cd <工程目录>
bash start.sh
# 访问 http://<设备IP>:7080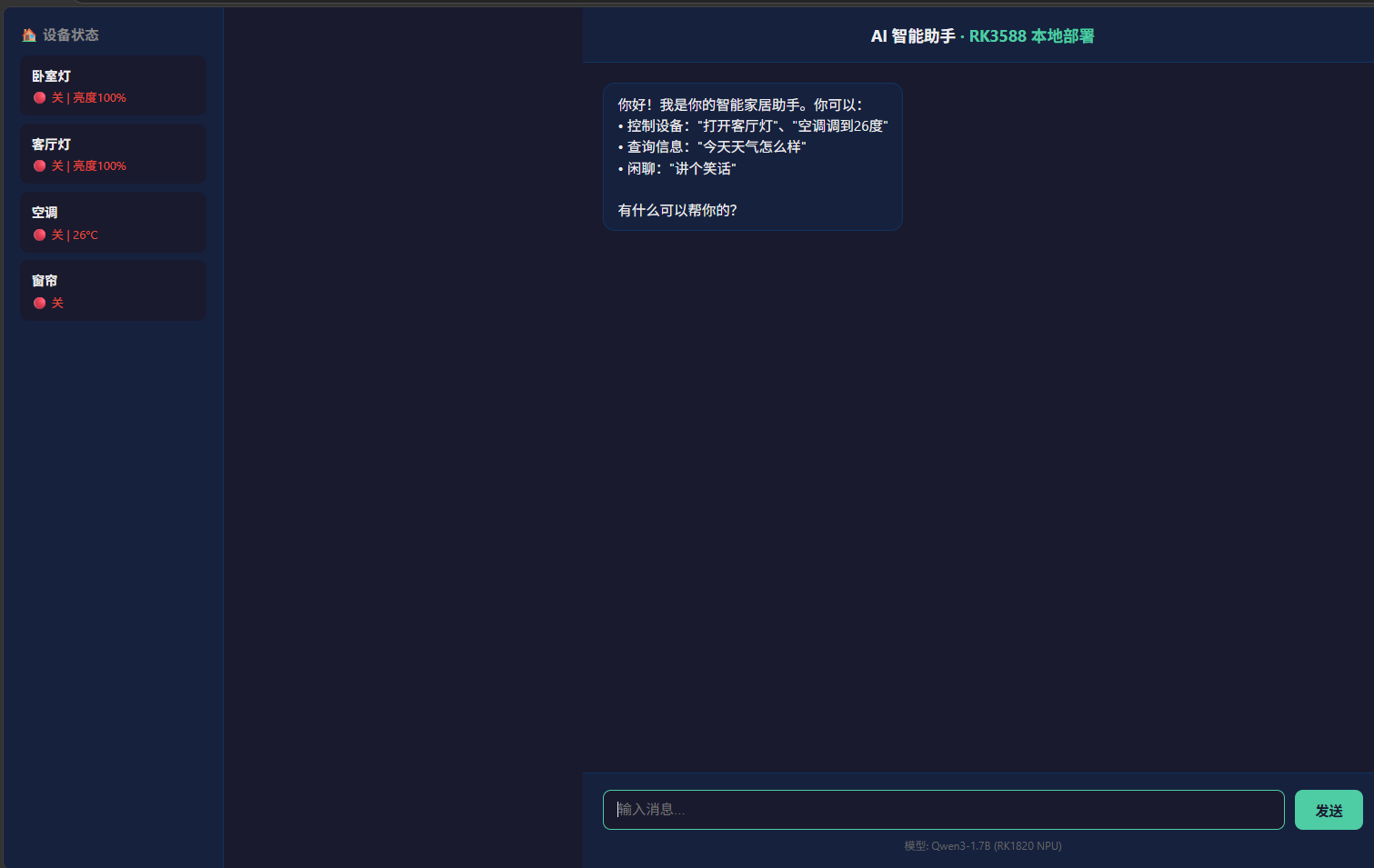
性能参考
rknn3_llm_demo 性能
| 指标 | 数值 |
|---|---|
| 首 Token 延迟 (TTFT) | ~63 ms |
| 每 Token 延迟 (TPOT) | ~8.3 ms |
| Prefill 速度 | ~317 tok/s |
| 生成速度 (TPS) | ~121 tok/s |
| NPU 显存占用 | ~1.4 GB / 5 GB |
rkllm3-server vs rknn3-toolkit-lite
| 维度 | rknn3-toolkit-lite (Python API) | rkllm3-server (HTTP) |
|---|---|---|
| 稳定性 | 高(进程内调用) | 偶发卡死 |
| VLM 支持 | 原生支持 | 有限 |
| 部署方式 | pip install wheel | deb 包 |
| 适用场景 | VLM/CNN/多模态 | 纯 LLM 对话 |
建议:VLM 场景使用 rknn3-toolkit-lite Python API,纯 LLM 对话场景使用 rkllm3-server。