01 NPU驱动与运行库架构
NPU(Neural Processing Unit,神经网络处理器)是一种专门用于人工智能计算的处理器,主要针对神经网络和深度学习算法进行了硬件级优化。与传统 CPU 和 GPU 相比,NPU 在执行矩阵运算、卷积运算等 AI 相关任务时具有更高的运算效率和更低的功耗,能够广泛应用于图像识别、语音识别、目标检测、智能安防以及大模型推理等场景。
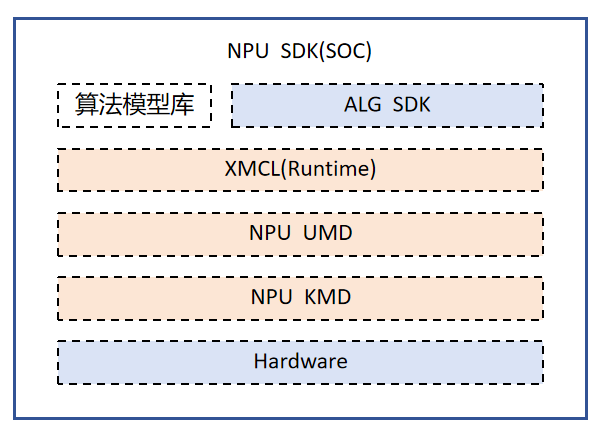
GK7206平台的NPU软件栈采用分层设计,旨在为开发者提供高效、灵活的深度神经网络应用开发环境。该架构涵盖了从底层硬件驱动到上层运行时库的完整链路,支持目标识别、图像分类等多种AI应用的开发。
1 软件栈分层
NPU的软件栈自上而下主要包括以下几个层次:
- 应用层与算法模型库 (ALG SDK):面向具体业务场景,提供目标检测、图像分类等现成的算法应用。典型示例位于
sample/npu/demo_ai/,包含人员检测、车辆检测、人脸识别等 21 种 AI 功能。 - 运行层 (XMEDIA_CL):作为针对NPU设计的异构编程框架,为上层应用提供C语言API库,负责模型加载、资源管理及任务调度,屏蔽底层硬件差异。核心头文件为
xmedia_cl.h和xmedia_cl_common.h,动态库为libxmedia_npu.so。 - 用户态驱动 (NPU UMD):负责封装具体的驱动调用逻辑,与运行层配合完成命令下发与数据交互。
- 内核态驱动 (NPU KMD):运行在Linux内核空间,负责NPU硬件的初始化、电源管理、中断处理、内存映射及任务队列的硬件级调度。内核模块为
xm_npu.ko,加载命令为./load xm7206v11a -i。 - 硬件:NPU计算单元,负责执行具体的神经网络算子指令。
2 核心架构特性
XMEDIA_CL框架在设计上具备以下关键特性,以保障NPU的高效利用:
- 零拷贝与Ping-Pong Buffer:支持零拷贝模式以减少内存搬运开销,同时支持Ping-Pong Buffer机制,实现数据流转与计算的重叠,提升吞吐率。
- 同步/异步模式:支持同步和异步两种调用模式。异步模式允许CPU与NPU并行工作,提高整体效率。
- JIT与AOT支持:支持即时编译(JIT)和提前编译(AOT),兼顾灵活性与极致性能。
- 异构设备扩展:支持CPU、NPU、DSP等异构设备的统一管理与调度。
- 低内存占用:内部无缓冲Buffer设计,无额外内存占用,适合资源受限的嵌入式场景。
3 NPU硬件规格
3.1 支持的数据类型
NPU计算单元支持以下数据类型(定义于 xmedia_cl_common.h):
| 数据类型 | 枚举值 | 说明 |
|---|---|---|
| INT8 | XMEDIA_CL_INT8 | 8位有符号整数,量化推理最常用的类型 |
| UINT8 | XMEDIA_CL_UINT8 | 8位无符号整数 |
| INT16 | XMEDIA_CL_INT16 | 16位有符号整数 |
| UINT16 | XMEDIA_CL_UINT16 | 16位无符号整数 |
| FP16 | XMEDIA_CL_FP16 | 半精度浮点数,平衡精度与性能 |
| INT32 | XMEDIA_CL_INT32 | 32位有符号整数 |
| FP32 | XMEDIA_CL_FP32 | 单精度浮点数,用于高精度场景 |
| INT4 | XMEDIA_CL_INT4 | 4位有符号整数,极致量化压缩 |
| UINT10 | XMEDIA_CL_UINT10 | 10位无符号整数,适用于RAW图像数据 |
| UINT12 | XMEDIA_CL_UINT12 | 12位无符号整数,适用于RAW图像数据 |
提示
实际部署中,大多数模型使用 INT8 量化,在精度损失极小的情况下获得最佳的推理性能。FP16 适用于对精度要求较高的场景。
3.2 支持的数据格式
| 格式 | 枚举值 | 说明 |
|---|---|---|
| RGB | XMEDIA_CL_FORMAT_RGB | 标准RGB三通道 |
| RGrGbB | XMEDIA_CL_FORMAT_RGrGbB | Bayer格式 |
| BGbGrR | XMEDIA_CL_FORMAT_BGbGrR | Bayer格式 |
| GrRBGb | XMEDIA_CL_FORMAT_GrRBGb | Bayer格式 |
| GbBRGr | XMEDIA_CL_FORMAT_GbBRGr | Bayer格式 |
| YUV | XMEDIA_CL_FORMAT_YUV | YUV色彩空间 |
| YVU | XMEDIA_CL_FORMAT_YVU | YVU色彩空间 |
3.3 NPU管理接口
NPU提供以下管理接口(定义于 xmedia_npu.h):
| API | 功能说明 |
|---|---|
xmedia_npu_set_quick_start_flag(flag) | 设置快速启动标志,开启后可加速NPU初始化 |
xmedia_npu_get_quick_start_flag(&flag) | 获取当前快速启动标志 |
xmedia_npu_get_proc_info(&proc) | 获取NPU内存映射信息(物理地址和缓冲区长度) |
xmedia_npu_get_usage_rate(&usage) | 获取NPU利用率(百分比),用于性能监控 |
以下示例展示如何查询NPU利用率:
#include "xmedia_npu.h"
xmedia_float usage = 0.0f;
xmedia_s32 ret = xmedia_npu_get_usage_rate(&usage);
if (ret == XMEDIA_SUCCESS) {
printf("NPU usage rate: %.2f%%\n", usage);
}4 核心数据类型
XMEDIA_CL框架定义了一组核心数据结构,用于描述模型的输入输出张量信息。
4.1 张量形状 (tensor_shape)
描述张量的维度信息:
typedef struct _xmedia_cl_tensor_shape {
xmedia_cl_u32 ndims; // 维度数量(最大 XMEDIA_CL_MAX_DIMS_NUM=8)
xmedia_cl_u32 dims[XMEDIA_CL_MAX_DIMS_NUM]; // 每个维度的大小
xmedia_cl_u32 pch[XMEDIA_CL_MAX_DIMS_NUM]; // 每个维度的步长(pitch)
xmedia_cl_data_type type; // 数据类型
} xmedia_cl_tensor_shape;例如,一个 NHWC 格式的输入张量 [1, 640, 640, 3],其 ndims=4,dims={1,640,640,3}。
4.2 张量量化参数 (tensor_quant)
描述量化推理所需的缩放因子和零点:
typedef struct _xmedia_cl_tensor_quant {
xmedia_cl_float scale; // 缩放因子
xmedia_cl_s32 zp; // 零点(zero point)
} xmedia_cl_tensor_quant;反量化公式为:real_value = (int8_value - zp) * scale
4.3 张量 (tensor)
完整的张量描述结构:
typedef struct _xmedia_cl_tensor {
xmedia_cl_u32 tensor_id; // 张量唯一标识
void *addr; // 数据缓冲区地址
xmedia_cl_tensor_shape shape; // 张量形状
xmedia_cl_tensor_quant quant; // 量化参数
xmedia_cl_u32 size; // 数据总大小(字节)
xmedia_cl_s8 *name; // 张量名称
} xmedia_cl_tensor;4.4 输入输出张量信息 (tensor_info_inout)
用于 xmedia_cl_graph_get_input/get_output 接口返回张量信息:
typedef struct _xmedia_cl_tensor_info_inout {
xmedia_cl_u32 num; // 张量数量
xmedia_cl_tensor *tensor; // 张量数组
xmedia_cl_tensor_batch *tensor_batch; // 批次信息(动态批处理时使用)
xmedia_cl_u32 *current_batch; // 当前批次大小
} xmedia_cl_tensor_info_inout;4.5 模型内存信息 (mem_info)
描述模型运行所需的各类内存大小,通过 xmedia_cl_graph_query_model_info_from_file 获取:
typedef struct _xmedia_cl_mem_info {
xmedia_cl_u32 worksize; // 工作空间大小
xmedia_cl_u32 weightsize; // 模型权重大小
xmedia_cl_u32 inputsize; // 输入缓冲区大小
xmedia_cl_u32 outputsize; // 输出缓冲区大小
xmedia_cl_u32 codesize; // 模型代码段大小
xmedia_cl_u32 memory_reuse_type; // 内存复用模式(见 3.6 节)
xmedia_cl_u32 private_data_size; // 私有数据大小
} xmedia_cl_mem_info;使用示例:
#include "xmedia_cl.h"
xmedia_cl_mem_info mem_info;
xmedia_cl_s32 ret = xmedia_cl_graph_query_model_info_from_file(
"model.xmm", &mem_info, XMEDIA_CL_MEM_INFO);
if (ret == XMEDIA_CL_SUCCESS) {
printf("workspace: %u bytes\n", mem_info.worksize);
printf("weight: %u bytes\n", mem_info.weightsize);
printf("input: %u bytes\n", mem_info.inputsize);
printf("output: %u bytes\n", mem_info.outputsize);
}4.6 内存复用模式
NPU支持四种内存复用模式,可有效降低多模型场景下的内存占用:
| 模式 | 枚举值 | 复用内容 |
|---|---|---|
| 仅工作空间复用 | XMEDIA_CL_WORKSPACE | workspace |
| 工作空间+输入复用 | XMEDIA_CL_WORKSPACE_INPUT | workspace + input |
| 工作空间+输出复用 | XMEDIA_CL_WORKSPACE_OUTPUT | workspace + output |
| 全部复用 | XMEDIA_CL_WORKSPACE_INPUT_OUTPUT | workspace + input + output |
可通过 xmedia_cl_graph_get_memory_reuse_type() 查询模型支持的复用模式。详细用法参见 XMM模型加载。
5 设备与上下文管理
5.1 设备类型
XMEDIA_CL框架支持以下异构设备类型:
| 设备类型 | 枚举值 | 说明 |
|---|---|---|
| CPU | XMEDIA_CL_DEVICE_CPU | 使用CPU执行推理 |
| NPU | XMEDIA_CL_DEVICE_NPU | 使用NPU加速执行推理 |
| ALL | XMEDIA_CL_DEVICE_ALL | 查询所有可用设备 |
5.2 上下文生命周期
上下文(Context)是XMEDIA_CL框架中管理所有资源的核心对象。典型的生命周期如下:
#include "xmedia_cl.h"
// 1. 初始化CL框架
xmedia_cl_s32 ret = xmedia_cl_init();
if (ret != XMEDIA_CL_SUCCESS) {
printf("CL init failed: %d\n", ret);
return -1;
}
// 2. 获取NPU设备ID
xmedia_cl_device_id devices = NULL;
xmedia_cl_u32 num_devices = 0;
ret = xmedia_cl_get_device_ids(XMEDIA_CL_DEVICE_NPU, &devices, &num_devices);
// 3. 创建上下文
xmedia_cl_s32 err_code = 0;
xmedia_cl_context context = xmedia_cl_create_context(
num_devices, &devices, &err_code);
if (context == NULL) {
printf("Create context failed: %d\n", err_code);
return -1;
}
// 4. 使用上下文进行模型加载和推理...
// (详见 ch03-xmm-model-loading.md)
// 5. 释放资源
xmedia_cl_release_context(context);
xmedia_cl_release_device_ids(&devices, &num_devices);
xmedia_cl_uninit();注意
上下文销毁前,必须确保所有使用该上下文的模型图(Graph)已通过 xmedia_cl_graph_unload() 卸载完毕。
6 错误码参考
XMEDIA_CL框架定义了详细的错误码(定义于 xmedia_cl_common.h),便于开发过程中快速定位问题。
6.1 通用错误
| 错误码 | 值 | 说明 |
|---|---|---|
XMEDIA_CL_SUCCESS | 0 | 操作成功 |
XMEDIA_CL_OUT_OF_HOST_MEMORY | -6 | 主机内存不足 |
XMEDIA_CL_INVALID_VALUE | -30 | 无效的参数值 |
XMEDIA_CL_INVALID_BUFFER_SIZE | -61 | 无效的缓冲区大小 |
6.2 设备与上下文错误
| 错误码 | 值 | 说明 |
|---|---|---|
XMEDIA_CL_INVALID_DEVICE_TYPE | -31 | 无效的设备类型 |
XMEDIA_CL_INVALID_PLATFORM | -32 | 无效的平台 |
XMEDIA_CL_INVALID_DEVICE | -33 | 无效的设备 |
XMEDIA_CL_INVALID_CONTEXT | -34 | 无效的上下文 |
XMEDIA_CL_INVALID_COMMAND_QUEUE | -36 | 无效的命令队列 |
6.3 模型加载错误
| 错误码 | 值 | 说明 |
|---|---|---|
XMEDIA_CL_INVALID_MODEL | -64 | 模型文件无效或格式不支持 |
XMEDIA_CL_READ_MODEL_FAIL | -65 | 读取模型文件失败 |
XMEDIA_CL_INVALID_BINARY | -42 | 无效的二进制数据 |
XMEDIA_CL_INVALID_PROGRAM | -44 | 无效的程序对象 |
XMEDIA_CL_ERROR_MODEL_TYPE | -68 | 模型类型错误 |
XMEDIA_CL_MODEL_DECOMPRESS_FAIL | -71 | 模型解压失败 |
XMEDIA_CL_NOT_FIND_FILE | -75 | 找不到模型文件 |
6.4 内存与地址错误
| 错误码 | 值 | 说明 |
|---|---|---|
XMEDIA_CL_INVALID_HOST_PTR | -37 | 无效的主机指针 |
XMEDIA_CL_INVALID_MEM_OBJECT | -38 | 无效的内存对象 |
XMEDIA_CL_INSUFFICIENT_SIZE | -66 | 内存大小不足 |
XMEDIA_CL_ERROR_ADDR_ALIGN | -69 | 地址未对齐(需8字节对齐) |
6.5 运行时错误
| 错误码 | 值 | 说明 |
|---|---|---|
XMEDIA_CL_INVALID_KERNEL | -48 | 无效的内核函数 |
XMEDIA_CL_INVALID_KERNEL_ARGS | -52 | 无效的内核参数 |
XMEDIA_CL_INVALID_OPERATION | -59 | 无效的操作 |
XMEDIA_CL_INVALID_UNINIT | -60 | CL框架未初始化 |
XMEDIA_CL_ALREADY_INIT | -63 | CL框架已初始化(重复初始化) |
XMEDIA_CL_OUT_OF_MAX_BATCH | -74 | 超出最大批次大小 |
6.6 事件错误
| 错误码 | 值 | 说明 |
|---|---|---|
XMEDIA_CL_WAIT_EVENT_FAILED | -56 | 等待事件失败 |
XMEDIA_CL_INVALID_EVENT_WAIT_LIST | -57 | 无效的事件等待列表 |
XMEDIA_CL_INVALID_EVENT | -58 | 无效的事件 |
7 核心概念与资源管理
XMEDIA_CL架构通过"上下文"统一管理各类设备资源,其核心概念如下:
- 设备:硬件计算单元,如NPU、CPU、DSP等。任务队列将命令排队到具体的设备上执行。
- 上下文:资源的管理者。负责管理各个设备、设备可访问的内存、每个设备对应的任务队列、程序和各个内核函数。
- 模型图文件:由编译器编译AI模型生成的二进制文件(.xmm格式),支持异构指令。
- 任务队列:用于将待执行的内核函数命令排队。
- 事件:用于标识任务的执行状态,并可通过事件显式建立任务间的依赖约束。
8 任务调度流程
上下文负责统一的设备资源管理。在运行过程中,用户首先加载模型文件,XMEDIA_CL会根据Graph结构自动创建程序对象和内核函数。创建完成后,XMEDIA_CL将内核函数放入任务队列中,并生成对应的事件。
异步执行机制:架构中的kernel函数执行均采用异步模式。用户向任务队列提交命令后,CPU可执行其它工作而无需等待NPU命令完成;如有必要等待命令完成,则可以通过事件显式地建立这个约束,从而实现CPU与NPU的最大化并行。
8.1 事件状态
任务提交后的执行状态如下:
| 状态 | 枚举值 | 说明 |
|---|---|---|
| QUEUED | XMEDIA_CL_QUEUED (0) | 已排队,等待执行 |
| SUBMITTED | XMEDIA_CL_SUBMITTED (1) | 已提交到设备 |
| RUNNING | XMEDIA_CL_RUNNING (2) | 正在执行 |
| COMPLETED | XMEDIA_CL_COMPLETED (3) | 执行完成 |
| FAILED | XMEDIA_CL_FAILED (4) | 执行失败 |
可通过 xmedia_cl_query_event_status() 查询当前状态,或通过 xmedia_cl_wait_for_events() 阻塞等待完成。
8.2 任务优先级
XMEDIA_CL支持4级任务优先级,可通过 xmedia_cl_graph_set_schedule_prio() 设置:
| 优先级 | 宏定义 | 值 |
|---|---|---|
| 最低 | XMEDIA_CL_JOB_SCHEDULE_PRIO_MIN | 0 |
| 中等 | XMEDIA_CL_JOB_SCHEDULE_PRIO_MEDIUM | 1 |
| 高 | XMEDIA_CL_JOB_SCHEDULE_PRIO_HIGH | 2 |
| 最高 | XMEDIA_CL_JOB_SCHEDULE_PRIO_MAX | 3 |
// 设置高优先级
xmedia_cl_graph_set_schedule_prio(graph, XMEDIA_CL_JOB_SCHEDULE_PRIO_HIGH);